


Làm chủ Odoo ORM, API và xử lý tác vụ nặng cho hệ thống lớn
Khi một hệ thống Odoo bắt đầu mở rộng, các vấn đề thường không đến từ việc thiếu tính năng, mà đến từ:
- Màn hình ngày càng chậm khi dữ liệu tăng
- Cron chạy lâu, lock database, user thao tác bị treo
- Compute field làm CPU tăng đột biến
- Tích hợp API bên ngoài lúc chạy được, lúc lỗi, rất khó debug
- Import / sync dữ liệu lớn bị timeout hoặc crash worker
Bài viết này tập trung vào kỹ thuật lập trình nâng cao trong Odoo, giúp bạn viết code:
- Chạy nhanh
- Ổn định trong production
- Dễ mở rộng khi dữ liệu và số user tăng
1. Odoo ORM nâng cao: Viết code ORM để hệ thống có thể scale
Odoo ORM rất mạnh, nhưng phần lớn vấn đề hiệu năng trong Odoo đến từ việc dùng ORM sai cách.
Tư duy cốt lõi:
ORM không chậm, nhưng ORM bị lạm dụng thì sẽ chậm
1.1 Recordset không phải là object đơn lẻ
Trong Odoo, self hầu như luôn là một recordset (tập record), kể cả khi chỉ có 1 record.
❌ Cách viết dễ gây chậm
for order in orders:
print(order.partner_id.name)
Nhìn qua thì đơn giản, nhưng rất dễ phát sinh N+1 query.
✅ Cách viết tối ưu hơn
partner_names = orders.mapped(‘partner_id.name’)
Nguyên tắc quan trọng:
- Tránh loop record nếu có thể xử lý theo batch
- Ưu tiên mapped, read, read_group
1.2 N+1 Query Problem – lỗi kinh điển trong ORM
Giả sử bạn có 5.000 đơn bán và muốn in ra tên sản phẩm:
for order in orders:
for line in order.order_line:
print(line.product_id.name)
Rất dễ xảy ra tình huống:
- 1 query lấy orders
- N query lấy order_line
- N query lấy product
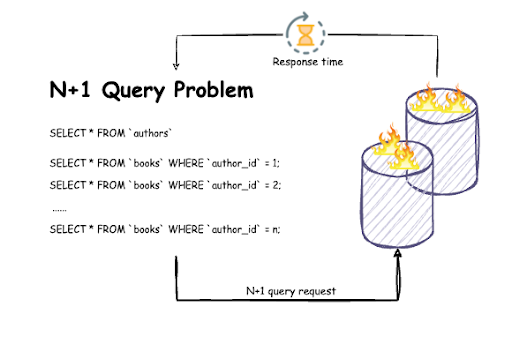


Cách xử lý tốt hơn
lines = orders.mapped(‘order_line’)
product_names = lines.mapped(‘product_id.name’)
ORM có thể prefetch và gom query, giảm đáng kể số lần truy cập database.
1.3 Chọn đúng ORM API theo mục đích
| Nhu cầu | API nên dùng |
| Lấy data đơn giản | search_read() |
| Thống kê / dashboard | read_group() |
| Logic nghiệp vụ | search() + recordset |
| Trích xuất field | mapped() |
| Lọc nhẹ | filtered() |
Ví dụ: Dashboard doanh thu
❌ Cộng bằng Python (chậm):
total = sum(self.env[‘sale.order’].search([]).mapped(‘amount_total’))
✅ Đẩy xuống database:
res = self.env[‘sale.order’].read_group(
[],
[‘amount_total:sum’],
[]
)
total = res[0][‘amount_total_sum’]
👉 Database làm tốt việc thống kê hơn Python rất nhiều.
1.4 Compute field – “sát thủ thầm lặng” của hiệu năng
Ví dụ sai phổ biến
@api.depends(‘partner_id’)
def _compute_sale_count(self):
for rec in self:
rec.sale_count = self.env[‘sale.order’].search_count([
(‘partner_id’, ‘=’, rec.partner_id.id)
])
Nếu có 1000 record → 1000 query.
Cách tối ưu bằng read_group
@api.depends(‘partner_id’)
def _compute_sale_count(self):
partners = self.mapped(‘partner_id’)
data = self.env[‘sale.order’].read_group(
[(‘partner_id’, ‘in’, partners.ids)],
[‘partner_id’],
[‘partner_id’],
lazy=False,
)
count_map = {d[‘partner_id’][0]: d[‘partner_id_count’] for d in data}
for rec in self:
rec.sale_count = count_map.get(rec.partner_id.id, 0)


Nguyên tắc compute field chuẩn production
- Không query trong loop
- Luôn batch
- Giảm số field trong @api.depends
- Compute nặng → cân nhắc store=True hoặc cron
1.5 Khi nào nên dùng SQL thuần?
SQL thuần không xấu, nhưng chỉ nên dùng khi:
- Query cực nặng
- ORM tạo query không tối ưu
- Bạn hiểu rõ nghiệp vụ
self.env.cr.execute(“””
UPDATE sale_order
SET x_synced = TRUE
WHERE state = ‘sale’
“””)
⚠️ Lưu ý:
- SQL bỏ qua compute, constraint Python
- Phải tự đảm bảo dữ liệu đúng
2. Lập trình Odoo API nâng cao & tích hợp hệ thống ngoài
Phần lớn hệ thống Odoo “chết dần” vì tích hợp viết sai kiến trúc.
2.1 Kiến trúc module tích hợp nên có
Cấu trúc gợi ý cho production:
integration_module/
├─ models/
├─ services/
├─ controllers/
├─ data/
- models: mapping dữ liệu
- services: xử lý logic & gọi API
- controllers: webhook / endpoint
- cron: xử lý async
2.2 Tuyệt đối không gọi API ngoài trong create() / write()
Vì sao rất nguy hiểm?
- User bị chờ lâu
- API lỗi → rollback toàn bộ transaction
- Dễ lock DB
Pattern đúng
- create/write chỉ lưu dữ liệu
- Tạo job
- Cron / worker xử lý
def write(self, vals):
res = super().write(vals)
self.env[‘integration.job’].create({
‘model’: self._name,
‘res_id’: self.id,
‘state’: ‘pending’
})
return res
2.3 Thiết kế HTTP client đúng chuẩn production
Một HTTP client tốt cần:
- timeout rõ ràng
- retry có kiểm soát
- log dễ debug
- tránh duplicate (idempotency)
response = requests.post(
url,
json=payload,
timeout=10
)
response.raise_for_status()
2.4 Webhook: nhanh – an toàn – async
Nguyên tắc:
- verify chữ ký
- tạo job
- trả 200 OK ngay
Không xử lý nặng trong controller.
3. Multi-threading & Multi-processing trong Odoo
Sự thật quan trọng:
Odoo ORM không thread-safe
3.1 Odoo xử lý song song như thế nào?
- Nhiều worker process
- Mỗi request = 1 process
- Không phải multi-thread
3.2 Vì sao không nên dùng Python threading với ORM?
- Cursor bị chia sẻ sai
- Cache ORM bị hỏng
- Lỗi ngẫu nhiên, rất khó debug
👉 Tránh threading nếu có ORM.
3.3 Cách đúng để xử lý tác vụ dài
Cách 1: Job queue / cron (khuyến nghị)
Flow:
User Action
↓
Create Job
↓
Cron / Worker
↓
Update Result
Cách 2: Chia batch
batch = self.search([(‘done’, ‘=’, False)], limit=2000)
batch.process()
batch.write({‘done’: True})
Cách 3: External worker (Celery, RQ)
Dùng khi:
- tác vụ nặng CPU
- dữ liệu cực lớn
- cần scale độc lập
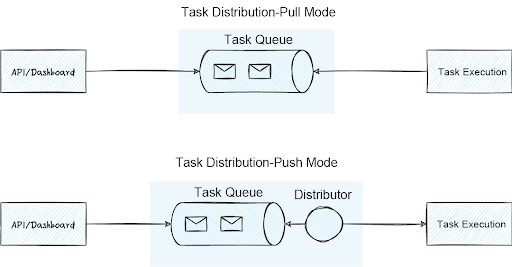
4. Checklist ORM & API trước khi lên production
- Không query trong loop
- Compute field đã batch
- Dashboard dùng read_group
- Không gọi API ngoài trong request user
- Task dài chạy async
- Batch size có giới hạn
- Có log & theo dõi job
Kết luận
Lập trình Odoo nâng cao không phải viết code phức tạp, mà là:
- Hiểu ORM hoạt động ra sao
- Biết chỗ nào cần database xử lý
- Thiết kế tích hợp bền vững
- Tôn trọng mô hình concurrency của Odoo
Nếu bạn làm chủ các kỹ thuật trong bài này, hệ thống Odoo của bạn sẽ:
- chạy ổn định khi dữ liệu tăng
- ít bug production
- dễ bảo trì và mở rộng lâu dài




Vui lòng đăng nhập để bình luận.