


Loop Engineering
Khi bạn không còn prompt cho agent nữa — mà thiết kế ra hệ thống tự prompt cho chúng
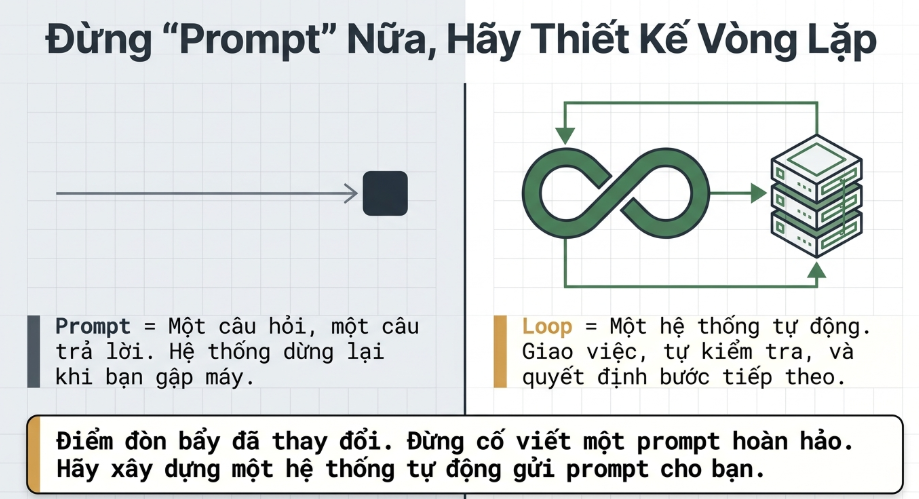
Loop engineering là việc bạn tự thay thế chính mình ở vai trò người ngồi gõ prompt cho agent. Thay vào đó, bạn thiết kế ra hệ thống làm việc đó thay bạn. Một “loop” ở đây có thể hiểu là một mục tiêu lặp (recursive goal): bạn định nghĩa mục đích, còn AI cứ thế lặp đi lặp lại cho tới khi hoàn thành. Về cơ bản nó gồm năm khối xây dựng (building blocks), và hiện cả Claude Code lẫn Codex đều đã có đủ cả năm.
Tôi tin đây có thể là tương lai của cách chúng ta làm việc với coding agent. Tuy nhiên mọi thứ vẫn còn rất sớm, bản thân tôi cũng còn hoài nghi, và bạn bắt buộc phải cẩn thận với chi phí token (mức tiêu thụ token có thể chênh lệch rất lớn tùy bạn “giàu” hay “nghèo” token). Bạn cũng vẫn cần một cách nào đó để đảm bảo chất lượng không bị tụt, và những lo ngại về “slop” (sản phẩm hời hợt, kém chất lượng do AI tạo ra hàng loạt) là hoàn toàn có cơ sở. Dù vậy, hãy cùng khám phá xem rốt cuộc đây là chuyện gì.
“Bạn không nên prompt cho coding agent nữa. Bạn nên thiết kế các loop để prompt cho agent của mình.” — @steipete
“Tôi không còn prompt cho Claude nữa. Tôi có các loop đang chạy, tự prompt cho Claude và tự quyết định việc cần làm. Công việc của tôi là viết loop.” — @bcherny, trưởng nhóm Claude Code tại Anthropic
Vậy tất cả những điều đó nghĩa là gì?
Suốt khoảng hai năm qua, cách bạn lấy được kết quả từ một coding agent là viết một prompt tốt và cung cấp đủ context (ngữ cảnh). Bạn gõ một thứ, đọc cái nó trả về, rồi gõ tiếp thứ kế tiếp. Agent là một công cụ và bạn cầm nắm nó suốt cả quá trình, hết lượt này tới lượt khác. Phần đó coi như sắp kết thúc — hoặc ít nhất nhiều người tin là vậy.
Giờ đây bạn dựng một hệ thống nhỏ: nó tự tìm việc, giao việc ra, kiểm tra lại, ghi lại những gì đã xong rồi tự quyết việc kế tiếp — và bạn để hệ thống đó “thúc” các agent thay vì chính bạn làm việc đó. Trước đây tôi từng viết về “người anh em họ” của khái niệm này — agent harness engineering, tức là xây dựng môi trường mà một agent đơn lẻ chạy bên trong, cùng mô hình “nhà máy” (factory model) — hệ thống dựng nên phần mềm. Loop engineering nằm cao hơn harness một tầng. Vẫn là harness đó, nhưng nó chạy theo lịch (timer), tự sinh ra những “trợ lý” nhỏ, và tự nuôi chính mình bằng đầu vào.
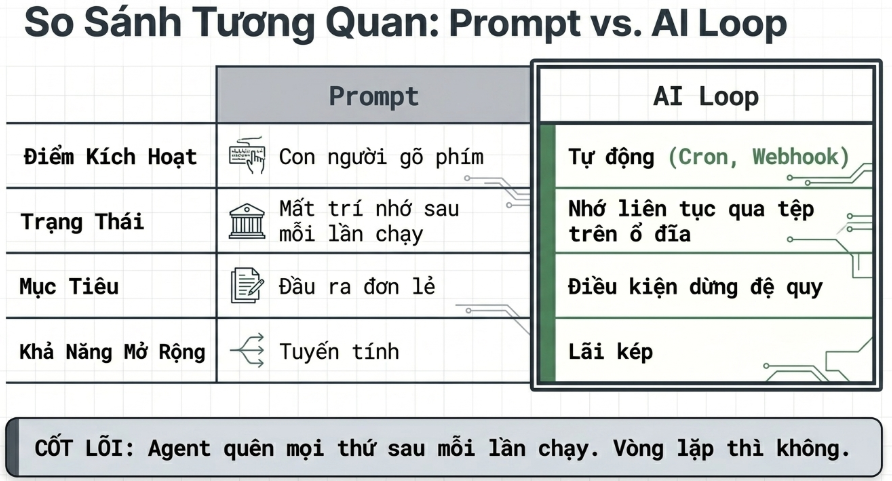
Điều khiến tôi bất ngờ là chuyện này không còn thực sự là vấn đề về công cụ nữa. Một năm trước, nếu muốn có một loop, bạn phải tự viết cả đống script bash, tự bảo trì đống đó mãi mãi, và nó là của riêng bạn — chỉ mình bạn hiểu. Giờ các mảnh ghép đã được tích hợp sẵn ngay trong sản phẩm. Danh sách các thành phần của Steinberger gần như khớp hoàn toàn với app Codex, rồi cũng gần như khớp y hệt với Claude Code. Và một khi bạn nhận ra hình hài của chúng giống nhau, bạn thôi tranh cãi xem nên dùng tool nào — bạn chỉ cần thiết kế một loop vẫn chạy được bất kể bạn đang ngồi trong tool nào.
Năm mảnh ghép, và vài ghi chú
Một loop cần năm thứ, và thêm một chỗ để “nhớ” mọi thứ. Hãy liệt kê trước rồi ánh xạ sau.
1. Automations — chạy theo lịch và tự mình làm việc discovery (phát hiện việc) và triage (phân loại, sắp xếp ưu tiên).
2. Worktrees — để hai agent làm việc song song mà không giẫm chân lên nhau.
3. Skills — để ghi lại kiến thức dự án mà nếu không có thì agent sẽ phải đoán.
4. Plugins & Connectors — để cắm agent vào những công cụ bạn vốn đã dùng.
5. Sub-agents — để một agent nảy ra ý tưởng, còn một agent khác kiểm tra lại ý tưởng đó.
Rồi đến thứ thứ sáu: bộ nhớ (memory). Một file markdown, hoặc một bảng Linear, bất cứ thứ gì sống bên ngoài cuộc hội thoại đơn lẻ và lưu lại những gì đã xong cùng những gì sắp tới. Nghe có vẻ quá đơn giản đến mức tưởng không quan trọng. Nhưng đây chính là mẹo mà mọi long-running agent (agent chạy lâu dài) đều dựa vào — tôi đã bàn kỹ trong bài về long-running agents: model quên sạch mọi thứ giữa các lần chạy, nên bộ nhớ phải nằm trên ổ đĩa chứ không nằm trong context. Agent thì quên, còn repo thì không.
Cả hai sản phẩm hiện đều đã có đủ cả năm.
Tên gọi có thể khác nhau đôi chỗ, nhưng năng lực thì như nhau. Hãy đi qua từng cái một, vì thành thật mà nói, chi tiết mới là nơi quyết định một loop trụ vững hay âm thầm rò rỉ khắp nơi.
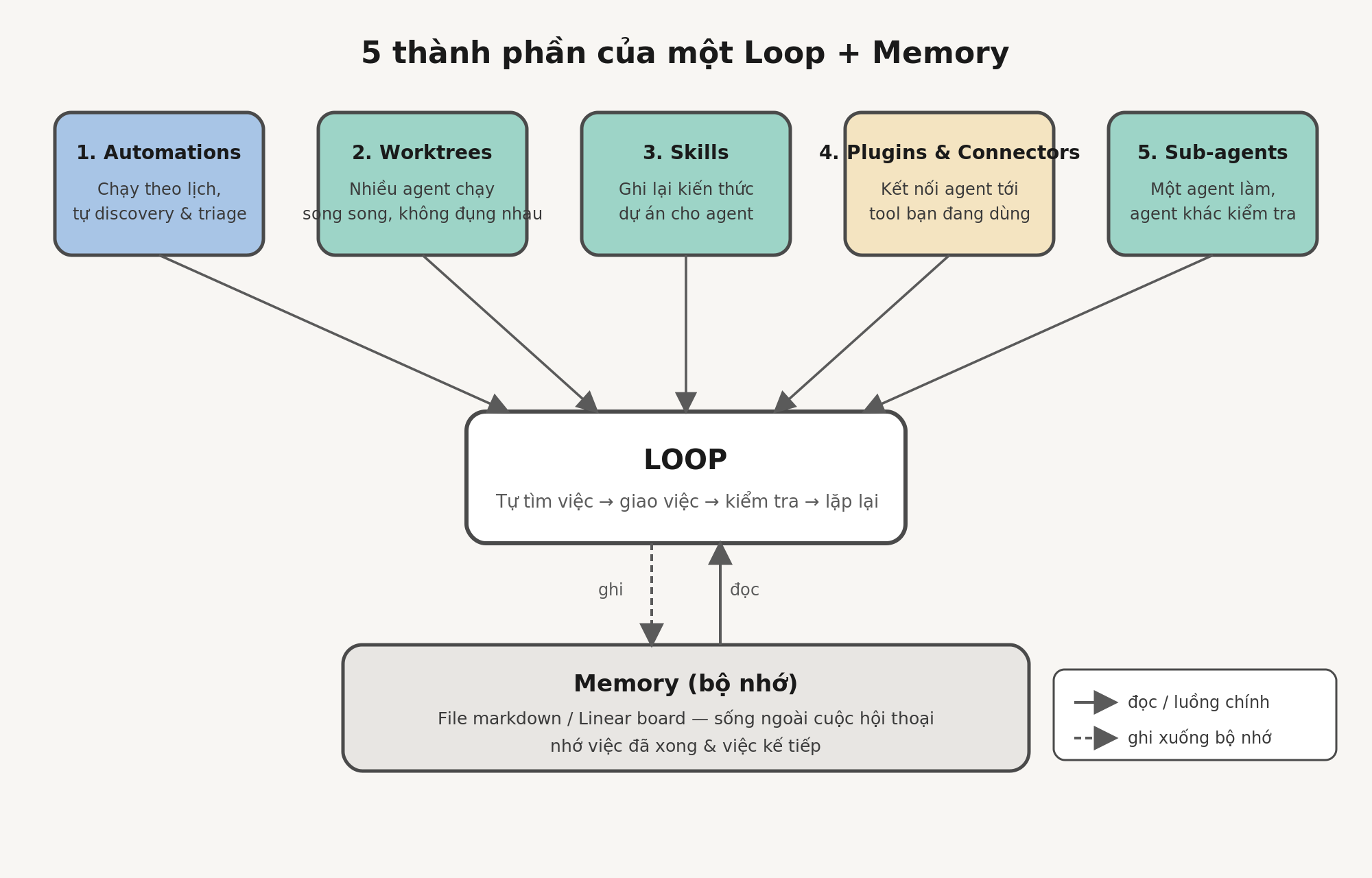
Hình 1 — Năm thành phần của một loop, đặt trên nền tảng bộ nhớ (memory).
Automations — đây là nhịp tim
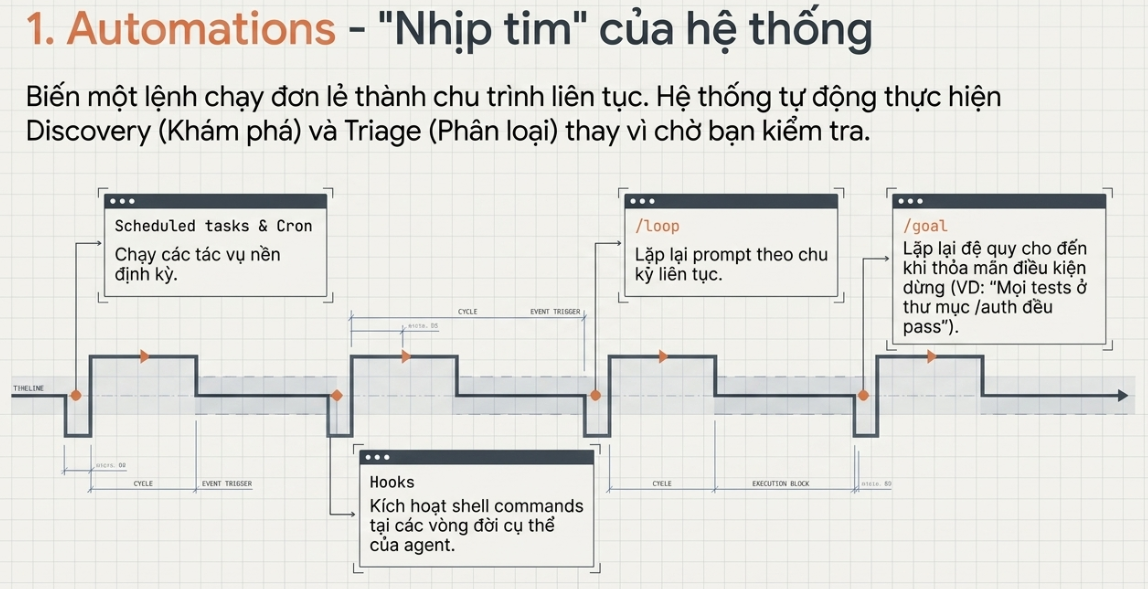
Automations chính là thứ biến một loop thành một loop thật sự, chứ không chỉ là một lần chạy bạn làm đúng một lần rồi thôi. Trong app Codex, bạn tạo một automation ở tab Automations, chọn project, chọn prompt nó sẽ chạy, tần suất bao lâu một lần, và chạy trên bản checkout local của bạn hay trên một background worktree. Những lần chạy phát hiện ra điều gì đó sẽ đi vào hộp Triage; còn những lần chạy không tìm thấy gì thì tự lưu trữ (archive) — khá tiện. OpenAI dùng chúng nội bộ cho những việc nhàm chán như triage issue hằng ngày, tóm tắt các lần CI thất bại, viết tóm tắt commit, hay đi “săn” những con bug mà ai đó vừa thêm vào tuần trước. Và một automation có thể gọi một skill, nên bạn giữ cho việc lặp lại dễ bảo trì: bạn “bắn” $ten-skill thay vì dán cả một bức tường hướng dẫn khổng lồ vào một lịch chạy mà sẽ chẳng ai buồn cập nhật.
Claude Code đạt tới đích tương tự nhưng qua scheduling và hooks. Bạn có thể chạy một prompt hoặc một lệnh theo chu kỳ bằng /loop, lên lịch một tác vụ cron, kích hoạt các lệnh shell tại những thời điểm nhất định trong vòng đời của agent bằng hooks, hoặc đẩy toàn bộ lên GitHub Actions nếu muốn nó tiếp tục chạy ngay cả khi bạn đã gập laptop lại. Cùng một ý tưởng y hệt: bạn định nghĩa một tác vụ tự động, gán cho nó một nhịp chạy, và kết quả tự tìm đến bạn — thay vì bạn phải đi vòng vòng tự kiểm tra.
Có một “nguyên thủy” (primitive) thứ hai chạy ngay trong phiên làm việc rất đáng biết, và nó gần với tinh thần của cả bài viết này nhất. /loop chạy lại theo một nhịp định sẵn. /goal thì cứ chạy mãi cho tới khi một điều kiện bạn viết ra thật sự đúng — và sau mỗi lượt, một model nhỏ riêng biệt sẽ kiểm tra xem đã xong hay chưa, nên agent viết code không phải là agent chấm điểm chính nó. Bạn đưa cho nó một thứ kiểu như “tất cả test trong test/auth đều pass và lint sạch” rồi bỏ đi làm việc khác. Codex cũng có đúng tính năng này, cũng gọi là /goal: nó tiếp tục làm việc xuyên suốt các lượt cho tới khi đạt một điều kiện dừng kiểm chứng được, có pause, resume và clear. Cùng một primitive, cả hai tool — và đó gần như là “mô-típ” của cả bài này.
Ví dụ thực tế cho người không chuyên
Hãy hình dung automation như một “nhân viên trực ca đêm” không bao giờ ngủ. Ví dụ: mỗi 7 giờ sáng, nó tự rà toàn bộ phản hồi lỗi từ hệ thống đêm qua, gom lại thành một danh sách ngắn gọn và đặt sẵn trên bàn làm việc của bạn — thay vì bạn phải tự mở 5 màn hình ra dò. Usecase khác: một automation chạy mỗi thứ Hai để tổng hợp các yêu cầu hỗ trợ khách hàng trong tuần và tự gắn nhãn “gấp / thường / chờ”.
Vậy đây là phần làm lộ ra công việc. Phần còn lại của loop là những gì hành động dựa trên nó.
Worktrees — để chạy song song không biến thành hỗn loạn
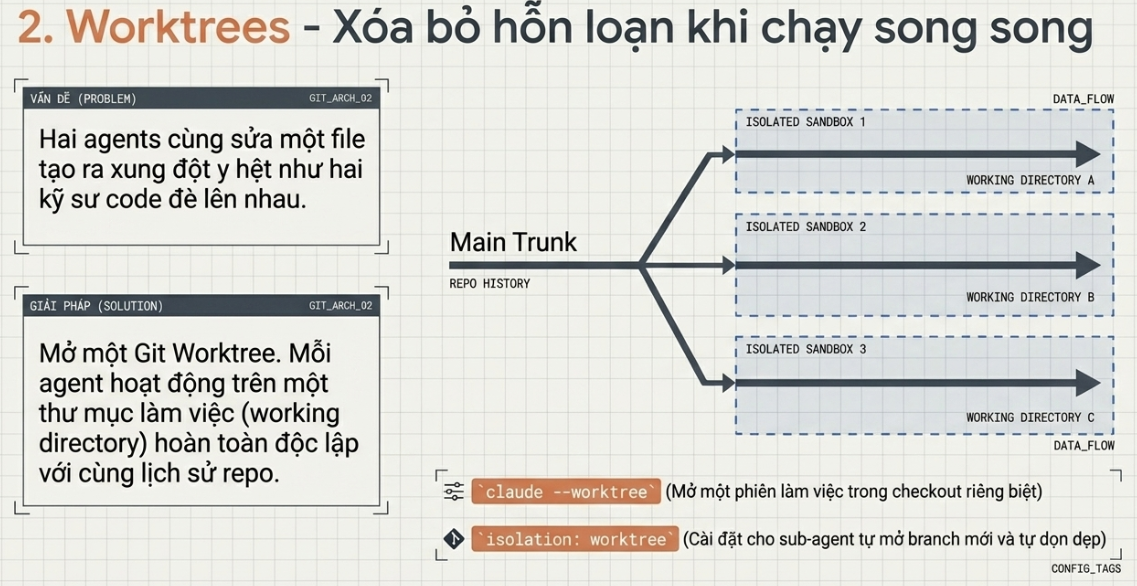
Ngay khoảnh khắc bạn chạy nhiều hơn một agent, các file bắt đầu va vào nhau, và đó chính là điểm gãy. Hai agent cùng ghi vào một file là đúng kiểu đau đầu y hệt như hai kỹ sư cùng commit vào chung những dòng code mà chẳng ai nói với ai trước. Một git worktree giải quyết chuyện đó: nó là một thư mục làm việc riêng nằm trên nhánh (branch) của riêng nó, chia sẻ chung lịch sử repo, nên các chỉnh sửa của một agent không thể nào động được tới bản checkout của agent kia.
Codex tích hợp sẵn hỗ trợ worktree, nên nhiều luồng (thread) cùng làm trên một repo một lúc mà không đụng nhau. Claude Code cho bạn mức cô lập tương tự với git worktree: một cờ –worktree để mở một phiên trong bản checkout riêng, và một thiết lập isolation: worktree mà bạn gắn lên một subagent để mỗi “trợ lý” nhận được một bản checkout mới tinh, tự dọn dẹp sau khi xong. Tôi đã viết về khía cạnh con người của tất cả chuyện này trong bài về “orchestration tax” (cái giá của việc điều phối): worktree gỡ bỏ va chạm về mặt cơ học, nhưng CHÍNH BẠN vẫn là trần giới hạn — băng thông review (khả năng đọc duyệt) của bạn mới quyết định bạn thật sự chạy được bao nhiêu agent, chứ không phải công cụ.
Skills — để bạn thôi phải giải thích lại dự án mỗi lần
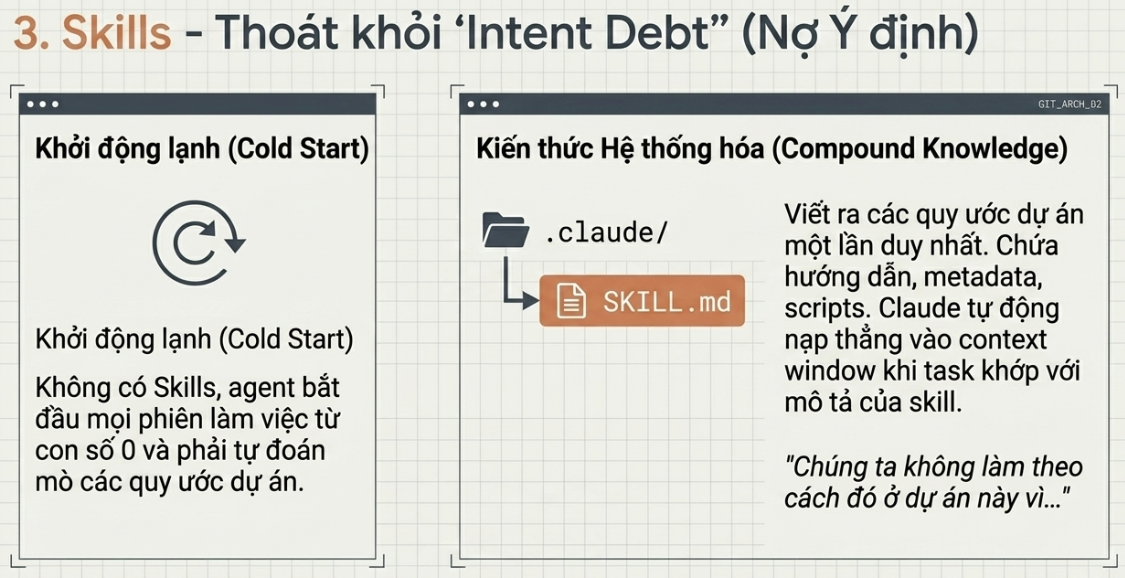
Một skill là cách bạn thôi phải giải thích lại cùng một context dự án mỗi phiên làm việc như một chú cá vàng (chỉ nhớ vài giây). Cả hai tool đều dùng chung một định dạng: một thư mục chứa một file SKILL.md bên trong, gồm hướng dẫn và metadata, rồi tùy chọn thêm script, tài liệu tham chiếu, tài nguyên. Codex chạy một skill khi bạn gọi nó bằng $ hoặc /skills, hoặc tự động khi tác vụ của bạn khớp với phần mô tả của skill — đó là lý do một mô tả chặt chẽ, “nhàm chán” lại ăn đứt một mô tả “bay bổng”. Claude Code cũng làm y như vậy, và tôi đã viết kỹ về mô-típ này trong bài agent skills.
Skills cũng là nơi “intent” (ý định) ngừng khiến bạn phải trả giá lặp đi lặp lại. Tôi đã lập luận trong bài “intent debt” (món nợ ý định) rằng một agent khởi đầu mỗi phiên ở trạng thái “lạnh” và sẽ lấp đầy mọi khoảng trống trong ý định của bạn bằng một phỏng đoán đầy tự tin. Một skill chính là ý định đó được viết ra bên ngoài: các quy ước, các bước build, cái kiểu “chúng ta không làm theo cách này vì cái sự cố lần đó” — viết một lần ở nơi mà agent đọc lại mỗi lần chạy. Không có skill thì loop phải suy ra lại toàn bộ dự án từ con số không mỗi vòng; có skill thì nó tích lũy dần (compound).
Một điều cần phân biệt rõ: skill là định dạng để soạn (authoring format), còn plugin là cách bạn đóng gói và phân phối nó. Khi muốn chia sẻ một skill giữa nhiều repo hoặc gói chung vài skill lại, bạn đóng gói chúng thành một plugin. Đúng với Codex, đúng với cả Claude Code.
Usecase: skill như “sổ tay nhập môn” cho nhân viên mới
Tưởng tượng mỗi lần có nhân viên mới, bạn lại phải kể lại từ đầu: “code style của team mình thế này, deploy theo các bước kia, đừng đụng vào module nọ vì từng gây sự cố.” Skill chính là cuốn sổ tay đó, nhưng dành cho agent — viết một lần, agent đọc lại mỗi lần làm việc. Ví dụ một skill `tao-bao-cao-doanh-thu` có thể ghi rõ: lấy dữ liệu từ đâu, làm tròn thế nào, đặt tên file ra sao.
Plugins & Connectors — để loop chạm được vào công cụ thật của bạn
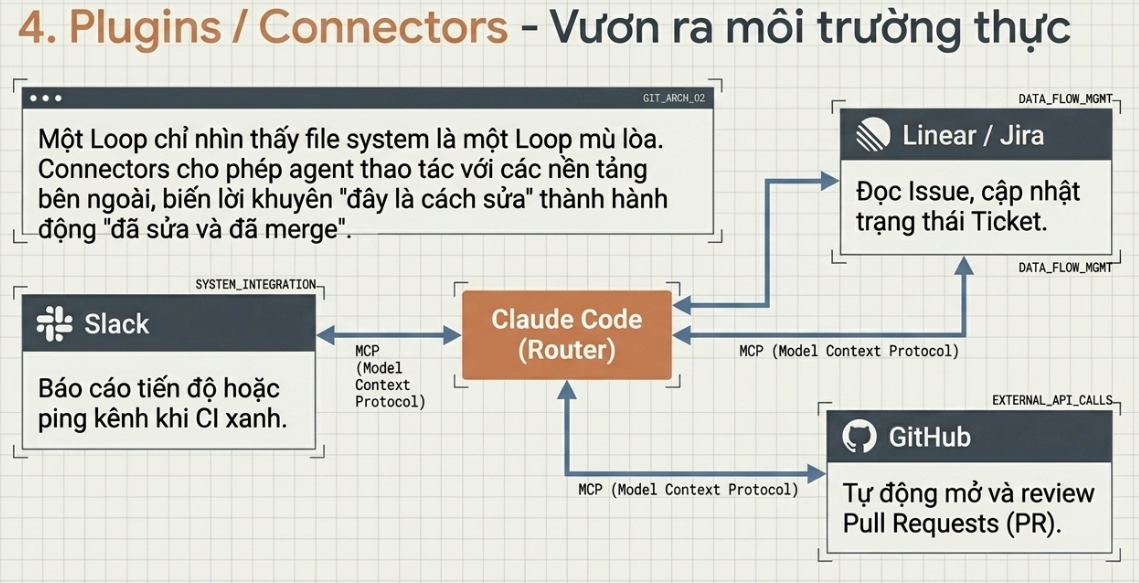
Một loop chỉ nhìn thấy được hệ thống file thôi thì là một loop tí hon. Connectors — vốn được xây trên nền MCP (Model Context Protocol) — cho phép agent đọc trình quản lý issue của bạn, truy vấn database, gọi tới một staging api, hay thả một tin nhắn vào Slack. Cả Codex lẫn Claude Code đều “nói” được MCP, nên connector bạn viết cho tool này thường dùng được luôn ở tool kia. Còn plugin thì gom connector và skill lại với nhau, để đồng đội của bạn cài đặt nguyên bộ setup chỉ trong một lần, thay vì phải dựng lại tất cả từ trí nhớ.
Đây chính là khác biệt giữa một agent chỉ nói “đây là cách sửa” và một loop tự mở PR, tự liên kết ticket Linear, và tự ping vào kênh chat ngay khi CI chuyển xanh. Connectors là lý do loop có thể hành động bên trong môi trường thật của bạn, thay vì chỉ kể cho bạn nghe nó sẽ làm gì nếu nó có thể.
Ví dụ: từ “gợi ý” thành “hành động trọn vẹn”
Không có connector: agent nói “bạn nên sửa dòng 42 và tạo PR.” Có connector: agent tự sửa, tự tạo PR, tự gắn ticket trên hệ thống quản lý công việc, rồi nhắn vào Slack: “Đã sửa xong bug đăng nhập, CI đã xanh, mời review.” Bạn chỉ việc bấm duyệt.
Sub-agents — tách người làm khỏi người kiểm
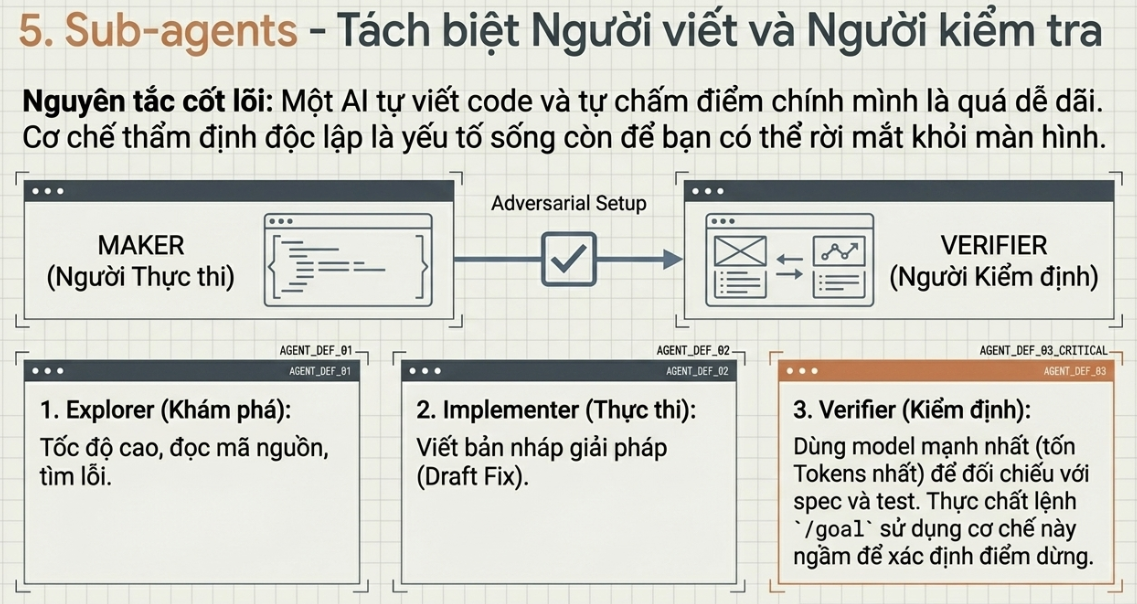
Thứ mang tính cấu trúc hữu ích nhất trong một loop, vượt xa mọi thứ khác, là tách người viết ra khỏi người kiểm. Model vừa viết code thì dễ dãi quá mức khi tự chấm bài của chính mình. Một agent thứ hai, với hướng dẫn khác và đôi khi là một model khác, sẽ bắt được những thứ mà agent đầu tiên đã tự “nói cho mình tin” là ổn.
Codex chỉ sinh ra subagent khi bạn yêu cầu, chạy chúng đồng thời rồi gộp kết quả lại thành một câu trả lời. Bạn tự định nghĩa agent của mình bằng các file TOML trong .codex/agents/, mỗi cái có một tên, một mô tả, hướng dẫn, cùng model và mức độ “reasoning effort” tùy chọn — nên agent reviewer bảo mật của bạn có thể là một model mạnh chạy ở mức nỗ lực cao, trong khi agent “explorer” lại là một thứ nhanh, chỉ đọc. Claude Code làm điều tương tự với subagent trong .claude/agents/ và các agent team chuyền việc cho nhau. Cách chia phổ biến ở cả hai là: một agent khám phá (explore), một agent hiện thực (implement), một agent đối chiếu lại với đặc tả (verify).
Tôi đã trình bày luận điểm này hai lần rồi, một lần dưới tên “code agent orchestra” (dàn nhạc các agent) và một lần là “adversarial code review” (review code theo kiểu đối kháng). Lý do nó đặc biệt quan trọng bên trong một loop là: loop chạy trong lúc bạn không ngồi canh, nên một “verifier” mà bạn thật sự tin tưởng mới là lý do duy nhất để bạn dám bỏ đi. Subagent đúng là tốn nhiều token hơn vì mỗi cái tự làm phần model và tool của riêng nó, nên hãy chi token vào những chỗ mà một ý kiến thứ hai xứng đáng để trả tiền. Đây cũng chính là điều mà /goal của Claude Code làm ở bên dưới: một model mới tinh quyết định loop đã xong hay chưa, thay vì chính model đã làm việc — tức là chính cái nguyên tắc tách người làm khỏi người kiểm, áp dụng lên cả điều kiện dừng.
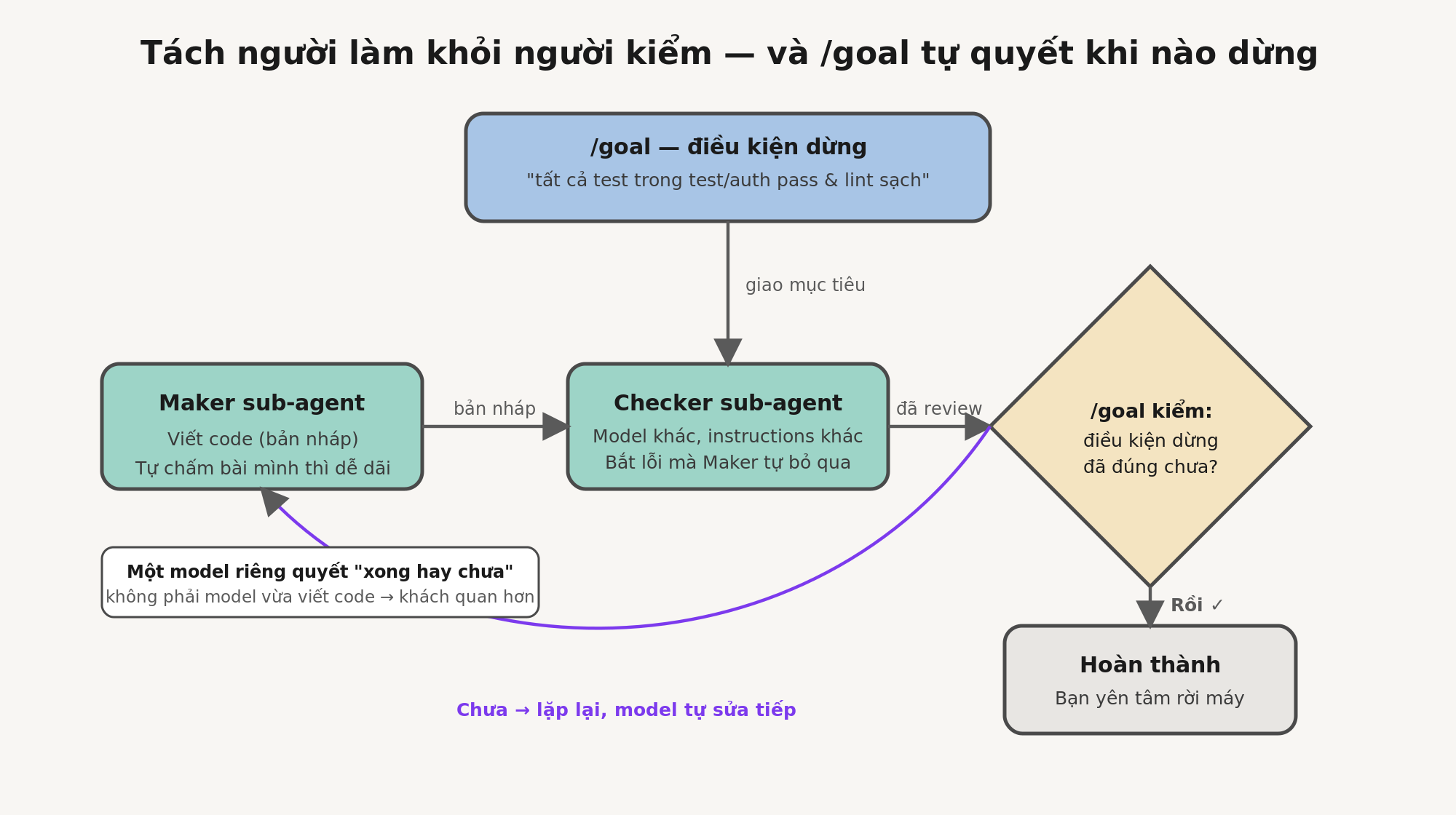
Hình 2 — Tách “người làm” (Maker) khỏi “người kiểm” (Checker), và /goal dùng một model riêng để quyết định khi nào dừng.
Ma trận kiến trúc tiêu chuẩn (Codex vs Claude Code)

Một loop trông như thế nào
Ghép tất cả lại, một luồng đơn lẻ biến thành một bảng điều khiển nhỏ. Đây là một hình hài tôi hay dùng đi dùng lại.
Một automation chạy mỗi sáng trên repo. Prompt của nó gọi một triage skill — skill này đọc các lần CI thất bại của ngày hôm qua, các issue đang mở, các commit gần đây, rồi ghi những phát hiện vào một file markdown hoặc một bảng Linear. Với mỗi phát hiện đáng làm, luồng đó mở một worktree cô lập và cử một sub-agent đi soạn bản fix, rồi một sub-agent thứ hai review bản nháp đó dựa trên các skill của dự án và các test đang có.
Connectors cho phép loop mở PR và cập nhật ticket. Bất cứ thứ gì loop không tự xử lý được sẽ rơi vào hộp triage để tôi xem. File trạng thái (state file) là xương sống của cả guồng máy: nó nhớ những gì đã thử, những gì đã pass, những gì còn mở — nhờ vậy sáng hôm sau lần chạy mới tiếp tục đúng chỗ hôm nay dừng lại.
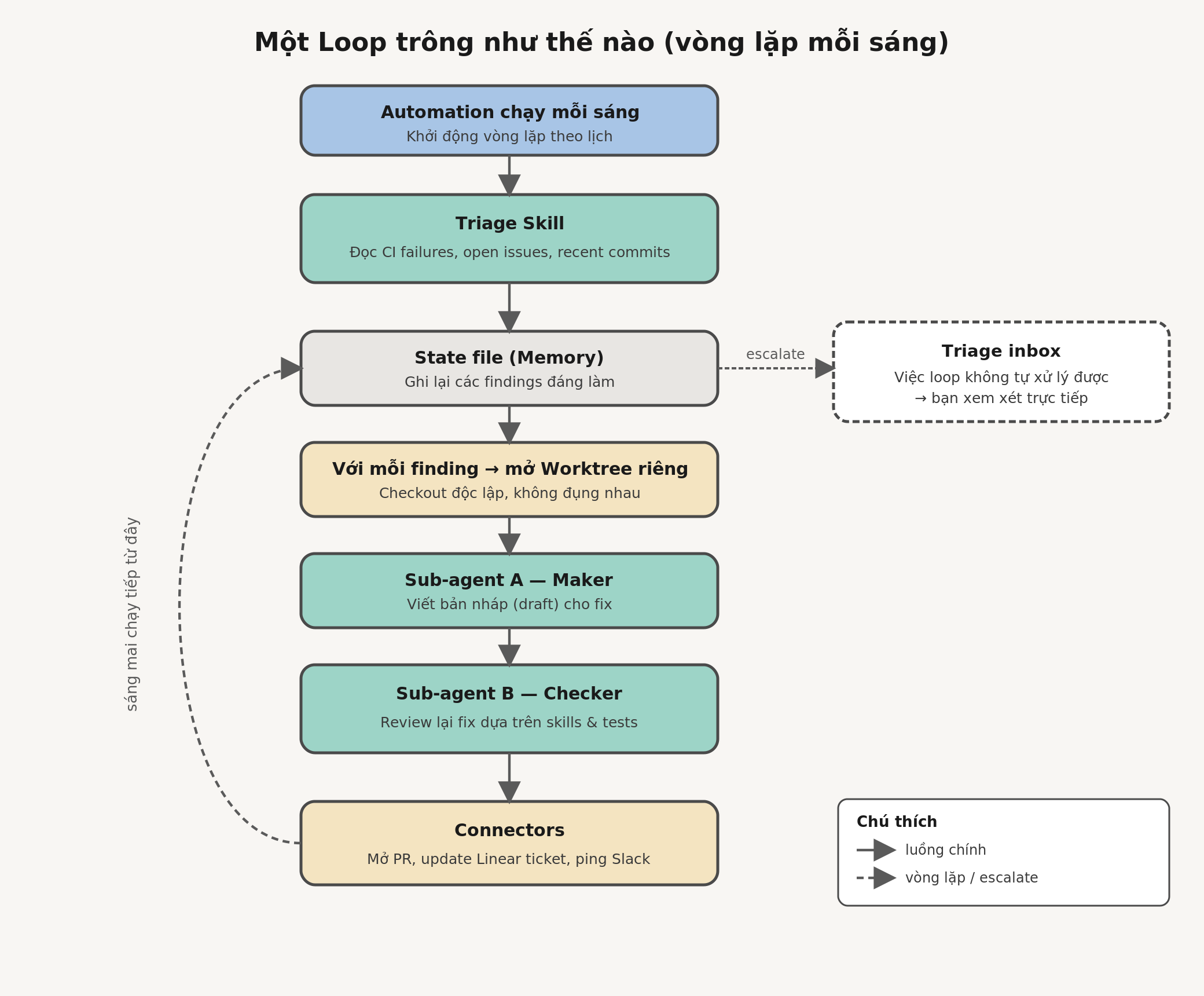
Hình 3 — Một vòng lặp hoàn chỉnh: automation buổi sáng → triage → worktree → maker/checker → connectors, với bộ nhớ làm xương sống.
Và hãy nhìn lại xem bạn vừa thật sự làm gì. Bạn thiết kế nó đúng một lần. Bạn không hề prompt cho bất kỳ bước nào trong số đó. Đó chính là luận điểm của Steinberger được biến thành hiện thực — và nó là cùng một loop dù trong Codex hay trong Claude Code, bởi vì các mảnh ghép là những mảnh ghép giống nhau.
Những gì loop vẫn không làm thay bạn
Loop thay đổi công việc, chứ không xóa bỏ bạn khỏi công việc. Và có ba vấn đề thực ra càng trở nên gắt hơn khi loop càng tốt lên, chứ không hề nhẹ đi.
Thứ nhất: việc kiểm chứng (verification) vẫn nằm trên vai bạn. Một loop chạy không người giám sát cũng là một loop phạm lỗi mà không ai giám sát. Toàn bộ lý do bạn tách sub-agent verifier ra khỏi maker là để cái “xong rồi” của loop có ý nghĩa thật sự — nhưng kể cả thế, “xong” vẫn chỉ là một lời tuyên bố, không phải một bằng chứng. Tôi vẫn nhắc lại câu cũ từ bài “code review trong thời đại AI”: công việc của bạn là ship đoạn code mà bạn đã xác nhận là chạy được.
Thứ hai: sự hiểu biết của bạn vẫn sẽ mục ruỗng nếu bạn cho phép điều đó. Loop càng ship nhanh đoạn code bạn không tự viết, thì khoảng cách giữa cái đang tồn tại và cái bạn thật sự nắm được càng lớn. Đó là “comprehension debt” (món nợ thấu hiểu), và một loop trơn tru chỉ khiến nó phình ra nhanh hơn — trừ khi bạn chịu đọc những gì loop đã làm.
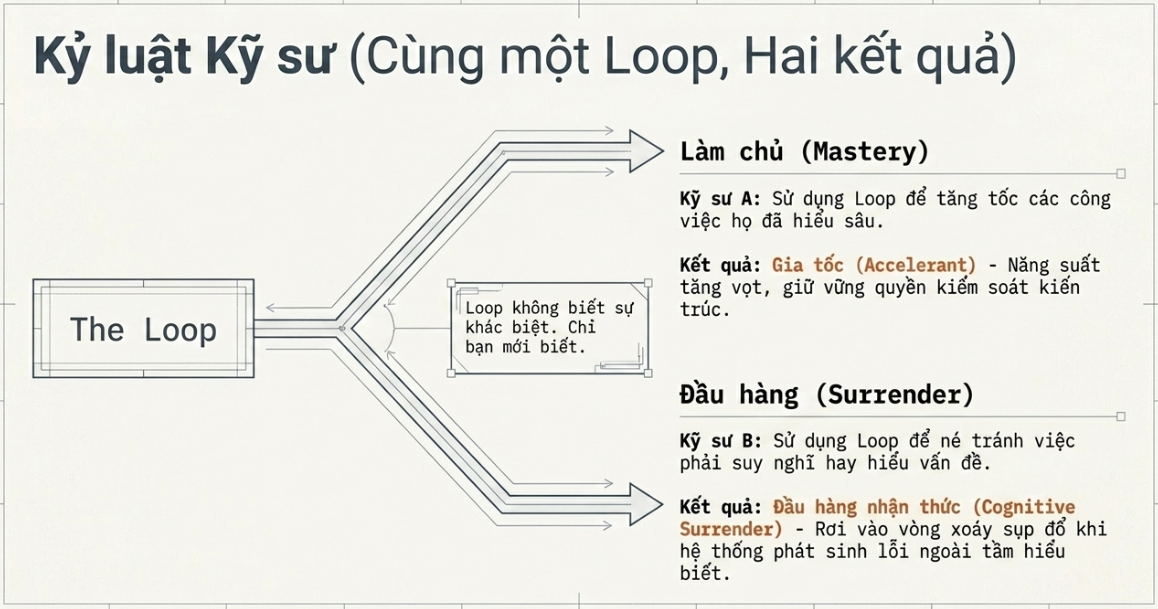
Và đúng vậy, tư thế thoải mái nhất hóa ra lại là tư thế rủi ro nhất. Khi loop tự chạy, rất dễ rơi vào cám dỗ thôi không còn chính kiến và cứ thế nhận bất cứ thứ gì nó trả về. Tôi gọi đó là “cognitive surrender” (đầu hàng về mặt nhận thức). Thiết kế loop là liều thuốc chữa khi bạn làm nó với sự phán đoán — và là chất xúc tác đẩy nhanh tai họa khi bạn làm nó để né việc phải suy nghĩ. Cùng một hành động, kết quả ngược nhau.

Hãy dựng loop. Nhưng vẫn là một kỹ sư.
Tôi nghĩ đây là một bản xem trước về cách công việc của chúng ta sẽ tiến hóa. Dù vậy, nếu tôi không tự review code của mình, hoặc nếu tôi phó mặc hoàn toàn cho các loop tự động sửa, thì chất lượng sản phẩm của tôi sẽ đi xuống. Nhiều khả năng tôi sẽ mắc kẹt trong một vòng xoáy đi xuống, càng lúc càng tự đào hố sâu hơn cho chính mình.
Vậy nên cứ thoải mái thiết lập các loop của bạn, nhưng đừng quên rằng việc prompt trực tiếp cho agent vẫn còn hiệu quả. Tất cả nằm ở chuyện tìm đúng điểm cân bằng.
Loop cũng có thể cho ra những kết quả khác nhau tùy vào chính bạn. Hai người dựng đúng một loop giống hệt nhau vẫn có thể nhận kết quả trái ngược hoàn toàn. Một người dùng nó để đi nhanh hơn trên công việc mà họ hiểu sâu. Người kia dùng nó để né việc phải hiểu công việc đó. Loop không biết phân biệt khác nhau. Còn bạn thì biết.
Đó chính là điều khiến thiết kế loop khó hơn prompt engineering, chứ không dễ hơn. Luận điểm của Cherny không phải là công việc đã trở nên dễ hơn. Mà là điểm tạo đòn bẩy đã dịch chuyển.
Hãy dựng loop. Nhưng hãy dựng nó như một người định ở lại làm kỹ sư, chứ không chỉ là người bấm nút “chạy”.






Vui lòng đăng nhập để bình luận.