


Phân tích chuyên sâu về những gì Anthropic, OpenAI, Perplexity và LangChain đang thực sự xây dựng. Bao gồm orchestration loop, tools, memory, context management, và mọi thứ biến một LLM không có trạng thái thành một agent thực sự có năng lực.
Bạn đã xây dựng một chatbot. Có thể bạn đã ghép một ReAct loop với vài tools. Nó hoạt động tốt khi demo. Rồi bạn thử xây dựng thứ gì đó production-grade, và mọi thứ bắt đầu đổ vỡ: model quên mất nó đã làm gì ba bước trước, các tool call thất bại âm thầm, và context window bị nhồi nhét đầy rác.
Vấn đề không phải ở model của bạn. Mà là ở mọi thứ xung quanh model đó.
LangChain đã chứng minh điều này khi họ chỉ thay đổi hạ tầng bao quanh LLM (cùng model, cùng weights) và nhảy từ ngoài top 30 lên hạng 5 trên TerminalBench 2.0. Một dự án nghiên cứu riêng đạt tỷ lệ pass 76,4% bằng cách để một LLM tự tối ưu hóa hạ tầng của chính nó, vượt qua các hệ thống được thiết kế thủ công.
Hạ tầng đó giờ đây có tên riêng: agent harness.
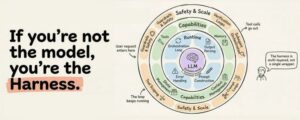
Agent Harness Là Gì?
Thuật ngữ này được chính thức hóa vào đầu năm 2026, nhưng khái niệm đã tồn tại từ trước đó rất lâu. Harness là toàn bộ hạ tầng phần mềm bao quanh một LLM: orchestration loop, tools, memory, context management, state persistence, error handling, và guardrails. Tài liệu Claude Code của Anthropic nói ngắn gọn: SDK là “agent harness cung cấp sức mạnh cho Claude Code.” Nhóm Codex của OpenAI dùng cách diễn đạt tương tự, đồng nhất hai khái niệm “agent” và “harness” để chỉ hạ tầng phi-model giúp LLM trở nên hữu ích.
Câu nói kinh điển từ Vivek Trivedy của LangChain rất đáng ghi nhớ: “Nếu bạn không phải là model, bạn chính là harness.”
Đây là điểm khiến nhiều người nhầm lẫn. “Agent” là hành vi nổi sinh: thực thể định hướng mục tiêu, sử dụng tools, tự sửa lỗi mà người dùng tương tác. Harness là cỗ máy tạo ra hành vi đó. Khi ai đó nói “tôi đã xây dựng một agent,” họ thực ra muốn nói rằng họ đã xây dựng một harness và trỏ nó vào một model.
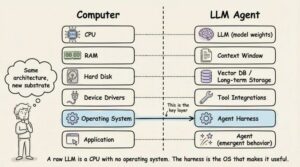
Beren Millidge đã làm rõ phép so sánh này trong bài luận năm 2023 “Scaffolded LLMs as Natural Language Computers.” Một LLM thuần túy giống như một CPU không có RAM, không có ổ đĩa, không có I/O. Context window đóng vai trò RAM (nhanh nhưng giới hạn). Các database bên ngoài hoạt động như ổ đĩa (dung lượng lớn nhưng chậm). Tool integration đóng vai trò driver thiết bị. Harness chính là hệ điều hành. Millidge viết: “Chúng ta đã tái phát minh kiến trúc Von Neumann” vì đây là sự trừu tượng hóa tự nhiên cho bất kỳ hệ thống máy tính nào.
Ba Tầng Kỹ Thuật
Ba tầng kỹ thuật đồng tâm bao quanh model:
- Prompt engineering — thiết kế các instructions mà model nhận được.
- Context engineering — quản lý những gì model thấy và khi nào.
- Harness engineering — bao gồm cả hai ở trên, cộng thêm toàn bộ hạ tầng ứng dụng: tool orchestration, state persistence, error recovery, verification loops, safety enforcement, và lifecycle management.
Harness không phải là một lớp bọc quanh prompt. Đó là hệ thống hoàn chỉnh giúp hành vi agent tự chủ trở nên khả thi.
12 Thành Phần Của Một Production Harness
Tổng hợp từ Anthropic, OpenAI, LangChain và cộng đồng practitioners, một production agent harness có mười hai thành phần riêng biệt. Hãy cùng đi qua từng thành phần.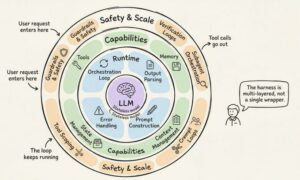
1. Orchestration Loop
Đây là nhịp tim của hệ thống. Nó triển khai chu kỳ Thought-Action-Observation (TAO), còn gọi là ReAct loop. Vòng lặp chạy: lắp ráp prompt → gọi LLM → phân tích output → thực thi các tool call → đưa kết quả trở lại → lặp lại cho đến khi hoàn thành.
Về mặt cơ học, nó thường chỉ là một vòng while. Sự phức tạp nằm ở tất cả những gì vòng lặp quản lý, chứ không phải bản thân vòng lặp. Anthropic mô tả runtime của họ là “dumb loop” — toàn bộ trí thông minh nằm trong model. Harness chỉ quản lý các lượt (turns).
2. Tools
Tools là đôi tay của agent. Chúng được định nghĩa dưới dạng schema (tên, mô tả, kiểu tham số) được inject vào context của LLM để model biết những gì khả dụng. Tầng tool xử lý việc đăng ký (registration), validate schema, trích xuất argument, thực thi trong sandbox, capture kết quả, và định dạng kết quả thành các observation mà LLM có thể đọc.
Claude Code cung cấp tools theo sáu nhóm: thao tác file, tìm kiếm, thực thi lệnh, truy cập web, code intelligence, và khởi tạo subagent. Agents SDK của OpenAI hỗ trợ function tools (qua @function_tool), hosted tools (WebSearch, CodeInterpreter, FileSearch), và MCP server tools.
3. Memory
Memory hoạt động ở nhiều khoảng thời gian. Short-term memory là lịch sử hội thoại trong một phiên duy nhất. Long-term memory tồn tại qua các phiên: Anthropic dùng file dự án CLAUDE.md và file MEMORY.md được tạo tự động; LangGraph dùng JSON Stores theo namespace; OpenAI hỗ trợ Sessions được lưu bằng SQLite hoặc Redis.
Claude Code triển khai cấu trúc ba tầng: một index nhẹ (~150 ký tự mỗi mục, luôn được tải), các file chủ đề chi tiết được kéo vào theo nhu cầu, và raw transcripts chỉ truy cập qua tìm kiếm. Nguyên tắc thiết kế quan trọng: agent coi memory của chính nó là “gợi ý” và xác minh lại với trạng thái thực tế trước khi hành động.
4. Context Management
Đây là nơi nhiều agent thất bại âm thầm. Vấn đề cốt lõi là context rot: hiệu suất model giảm 30%+ khi nội dung quan trọng rơi vào vị trí giữa context window (nghiên cứu của Chroma, được Stanford xác nhận qua kết quả “Lost in the Middle”). Ngay cả context window hàng triệu token cũng bị giảm khả năng tuân theo instruction khi context phình to.
Các chiến lược production bao gồm:
- Compaction: tóm tắt lịch sử hội thoại khi sắp đạt giới hạn (Claude Code giữ lại các quyết định kiến trúc và bug chưa giải quyết, loại bỏ tool output dư thừa).
- Observation masking: Junie của JetBrains ẩn các tool output cũ trong khi vẫn giữ tool call hiển thị.
- Just-in-time retrieval: duy trì các identifier nhẹ và tải dữ liệu động (Claude Code dùng grep, glob, head, tail thay vì tải toàn bộ file).
- Sub-agent delegation: mỗi subagent khám phá rộng rãi nhưng chỉ trả về bản tóm tắt cô đọng 1.000 đến 2.000 token.
Hướng dẫn context engineering của Anthropic nêu rõ mục tiêu: tìm tập token nhỏ nhất có thể chứa thông tin có giá trị cao nhất để tối đa hóa khả năng đạt kết quả mong muốn.
5. Prompt Construction
Bước này lắp ráp những gì model thực sự thấy ở mỗi bước. Nó có cấu trúc phân cấp: system prompt, tool definitions, memory files, lịch sử hội thoại, và tin nhắn hiện tại của người dùng.
Codex của OpenAI dùng một priority stack nghiêm ngặt: system message do server kiểm soát (ưu tiên cao nhất), tool definitions, developer instructions, user instructions (các file AGENTS.md dạng cascade, giới hạn 32 KiB), rồi đến lịch sử hội thoại.
6. Output Parsing
Các harness hiện đại dựa vào native tool calling, nơi model trả về các đối tượng tool_calls có cấu trúc thay vì free-text cần parse. Harness kiểm tra: có tool call không? Thực thi và lặp. Không có tool call? Đó là câu trả lời cuối cùng.
Với structured output, cả OpenAI và LangChain đều hỗ trợ response bị ràng buộc bởi schema qua Pydantic models. Các cách tiếp cận cũ như RetryWithErrorOutputParser (đưa lại prompt gốc, completion thất bại và lỗi parse về cho model) vẫn khả dụng cho các edge case.
7. State Management
LangGraph mô hình hóa state như các typed dictionary chảy qua các graph node, với reducer hợp nhất các cập nhật. Checkpointing xảy ra tại ranh giới super-step, cho phép resume sau khi bị gián đoạn và debug time-travel. OpenAI cung cấp bốn chiến lược độc lập: application memory, SDK sessions, server-side Conversations API, hoặc lightweight previous_response_id chaining. Claude Code có cách tiếp cận khác: git commit là checkpoint và progress file là structured scratchpad.
8. Error Handling
Đây là lý do tại sao điều này quan trọng: một quy trình 10 bước với tỷ lệ thành công 99% mỗi bước vẫn chỉ có ~90,4% thành công end-to-end. Lỗi tích lũy rất nhanh.
LangGraph phân biệt bốn loại lỗi: transient (retry với backoff), LLM-recoverable (trả lỗi về dưới dạng ToolMessage để model điều chỉnh), user-fixable (dừng để hỏi người dùng), và unexpected (đẩy lên để debug). Anthropic bắt lỗi trong tool handler và trả về kết quả lỗi để giữ vòng lặp tiếp tục. Production harness của Stripe giới hạn số lần retry tối đa là hai.
9. Guardrails và Safety
SDK của OpenAI triển khai ba tầng: input guardrails (chạy trên agent đầu tiên), output guardrails (chạy trên output cuối cùng), và tool guardrails (chạy trên mọi lần gọi tool). Cơ chế “tripwire” dừng agent ngay lập tức khi bị kích hoạt.
Anthropic tách biệt việc thực thi quyền hạn (permission enforcement) khỏi lý luận của model về mặt kiến trúc. Model quyết định sẽ thử gì; hệ thống tool quyết định cái gì được phép. Claude Code kiểm soát ~40 tool capability riêng lẻ một cách độc lập, với ba giai đoạn: thiết lập trust khi tải project, kiểm tra quyền trước mỗi tool call, và yêu cầu xác nhận rõ ràng từ người dùng cho các thao tác rủi ro cao.
10. Verification Loops
Đây là điều phân biệt demo đồ chơi với production agent. Anthropic khuyến nghị ba cách: rules-based feedback (tests, linters, type checkers), visual feedback (screenshot qua Playwright cho UI tasks), và LLM-as-judge (một subagent riêng biệt đánh giá output).
Boris Cherny, người tạo ra Claude Code, lưu ý rằng việc cho model một cách để xác minh công việc của nó cải thiện chất lượng từ 2 đến 3 lần.
11. Subagent Orchestration
Claude Code hỗ trợ ba execution model: Fork (sao chép byte-identical từ context của parent), Teammate (terminal pane riêng với giao tiếp qua file-based mailbox), và Worktree (git worktree riêng, branch độc lập cho mỗi agent). SDK của OpenAI hỗ trợ agents-as-tools (specialist xử lý subtask giới hạn) và handoffs (specialist tiếp quản hoàn toàn). LangGraph triển khai subagent dưới dạng nested state graph.
Vòng Lặp Trong Thực Tế: Hành Trình Từng Bước
Giờ bạn đã biết các thành phần, hãy cùng theo dõi cách chúng phối hợp với nhau trong một chu kỳ đơn.
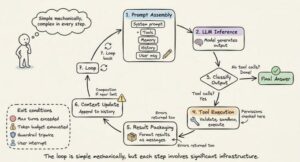
Bước 1 (Prompt Assembly): Harness xây dựng toàn bộ input: system prompt + tool schemas + memory files + lịch sử hội thoại + tin nhắn hiện tại của người dùng. Ngữ cảnh quan trọng được đặt ở đầu và cuối prompt (kết quả từ nghiên cứu “Lost in the Middle”).
Bước 2 (LLM Inference): Prompt đã được lắp ráp gửi đến model API. Model tạo ra output token: text, tool call request, hoặc cả hai.
Bước 3 (Output Classification): Nếu model tạo ra text mà không có tool call, vòng lặp kết thúc. Nếu có tool call, tiến hành thực thi. Nếu có yêu cầu handoff, cập nhật agent hiện tại và khởi động lại.
Bước 4 (Tool Execution): Với mỗi tool call, harness validate argument, kiểm tra quyền, thực thi trong môi trường sandbox, và capture kết quả. Các thao tác read-only có thể chạy đồng thời; các thao tác write chạy tuần tự.
Bước 5 (Result Packaging): Kết quả tool được định dạng thành message mà LLM có thể đọc. Lỗi được bắt và trả về dưới dạng error result để model tự sửa.
Bước 6 (Context Update): Kết quả được thêm vào lịch sử hội thoại. Nếu sắp chạm giới hạn context window, harness kích hoạt compaction.
Bước 7 (Loop): Quay lại Bước 1. Lặp lại cho đến khi kết thúc.
Điều kiện kết thúc được xếp tầng: model tạo ra response không có tool call, vượt quá giới hạn số lượt tối đa, cạn kiệt token budget, guardrail tripwire kích hoạt, người dùng ngắt, hoặc trả về safety refusal. Một câu hỏi đơn giản có thể mất 1 đến 2 lượt. Một task refactoring phức tạp có thể xâu chuỗi hàng chục tool call qua nhiều lượt.
Với các task chạy dài spanning nhiều context window, Anthropic đã phát triển mô hình “Ralph Loop” hai giai đoạn: một Initializer Agent thiết lập môi trường (init script, progress file, feature list, git commit ban đầu), sau đó một Coding Agent trong mỗi phiên tiếp theo đọc git log và progress file để định hướng, chọn feature ưu tiên cao nhất chưa hoàn thành, làm việc với nó, commit, và viết tóm tắt. Filesystem cung cấp tính liên tục xuyên suốt các context window.
Cách Các Framework Thực Tế Triển Khai
Anthropic’s Claude Agent SDK mở ra harness thông qua một hàm query() tạo agentic loop và trả về async iterator streaming messages. Runtime là “dumb loop.” Toàn bộ trí thông minh nằm trong model. Claude Code dùng chu kỳ Gather-Act-Verify: thu thập context (tìm kiếm file, đọc code), thực hiện hành động (chỉnh sửa file, chạy lệnh), xác minh kết quả (chạy test, kiểm tra output), lặp lại.
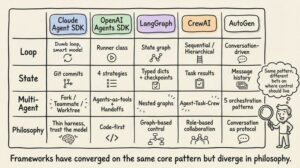
OpenAI’s Agents SDK triển khai harness qua lớp Runner với ba mode: async, sync, và streamed. SDK theo hướng “code-first”: logic workflow được biểu diễn bằng Python thuần thay vì graph DSL. Harness của Codex mở rộng với kiến trúc ba tầng: Codex Core (agent code + runtime), App Server (bidirectional JSON-RPC API), và client surfaces (CLI, VS Code, web app). Tất cả surfaces dùng chung harness, đó là lý do “Codex models cảm thấy tốt hơn trên Codex surfaces so với cửa sổ chat thông thường.”
LangGraph mô hình hóa harness như một explicit state graph. Hai node (llm_call và tool_node) được nối bởi conditional edge: nếu có tool call, định tuyến đến tool_node; nếu không, định tuyến đến END. LangGraph phát triển từ AgentExecutor của LangChain, thứ đã bị deprecated ở v0.2 vì khó mở rộng và thiếu hỗ trợ multi-agent. Deep Agents của LangChain dùng rõ ràng thuật ngữ “agent harness”: built-in tools, planning (write_todos tool), file systems cho context management, khởi tạo subagent, và persistent memory.
CrewAI triển khai kiến trúc multi-agent dựa trên vai trò: Agent (harness bao quanh LLM, được định nghĩa bởi role, goal, backstory và tools), Task (đơn vị công việc), và Crew (tập hợp các agent). Tầng Flows của CrewAI thêm “backbone xác định với trí thông minh ở nơi quan trọng,” quản lý routing và validation trong khi Crew xử lý cộng tác tự chủ.
AutoGen (đang phát triển thành Microsoft Agent Framework) đã tiên phong trong conversation-driven orchestration. Kiến trúc ba tầng (Core, AgentChat, Extensions) hỗ trợ năm orchestration pattern: sequential, concurrent (fan-out/fan-in), group chat, handoff, và magentic (một manager agent duy trì dynamic task ledger phối hợp các specialist).
Phép Ẩn Dụ Giàn Giáo
Phép ẩn dụ giàn giáo (scaffolding) không chỉ là hình ảnh trang trí. Nó chính xác. Giàn giáo xây dựng là hạ tầng tạm thời cho phép công nhân xây dựng một công trình mà họ không thể tiếp cận được bằng cách khác. Giàn giáo không làm công việc xây dựng. Nhưng nếu không có nó, công nhân không thể lên tầng cao.
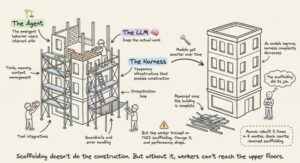
Điểm mấu chốt: giàn giáo được tháo dỡ khi tòa nhà hoàn thành. Khi model ngày càng mạnh, độ phức tạp của harness phải giảm. Manus đã được xây dựng lại năm lần trong sáu tháng, mỗi lần viết lại loại bỏ thêm sự phức tạp. Các tool definition phức tạp trở thành thực thi shell tổng quát. “Management agent” trở thành các structured handoff đơn giản.
Điều này chỉ ra nguyên tắc đồng tiến hóa: model hiện nay được post-training với các harness cụ thể trong vòng lặp. Model của Claude Code đã học cách sử dụng harness cụ thể mà nó được huấn luyện. Thay đổi cách triển khai tool có thể làm giảm hiệu suất vì sự gắn kết chặt chẽ này.
“Bài kiểm tra tương thích tương lai” cho thiết kế harness: nếu hiệu suất tăng theo với các model mạnh hơn mà không cần thêm độ phức tạp vào harness, thì thiết kế đó là đúng đắn.
Bảy Quyết Định Định Hình Mọi Harness
Mọi kiến trúc sư harness đều phải đối mặt với bảy lựa chọn:
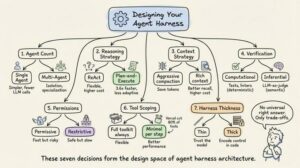
- Single-agent vs. multi-agent. Cả Anthropic và OpenAI đều khuyên: tối đa hóa một single agent trước. Hệ thống multi-agent thêm overhead (LLM call phụ cho routing, context bị mất trong quá trình handoff). Chỉ tách khi tool overload vượt ~10 tools chồng chéo hoặc tồn tại các task domain rõ ràng tách biệt.
- ReAct vs. plan-and-execute. ReAct xen kẽ reasoning và action ở mỗi bước (linh hoạt nhưng chi phí cao hơn mỗi bước). Plan-and-execute tách biệt planning khỏi execution. LLMCompiler báo cáo tăng tốc 3,6 lần so với sequential ReAct.
- Chiến lược context window management. Năm cách tiếp cận production: time-based clearing, conversation summarization, observation masking, structured note-taking, và sub-agent delegation. Nghiên cứu ACON cho thấy giảm 26 đến 54% token trong khi vẫn bảo toàn độ chính xác 95%+ bằng cách ưu tiên reasoning trace hơn raw tool output.
- Thiết kế verification loop. Computational verification (tests, linters) cung cấp ground truth xác định. Inferential verification (LLM-as-judge) bắt được các vấn đề ngữ nghĩa nhưng tăng latency. Nhóm Thoughtworks của Martin Fowler đóng khung điều này là guides (feedforward, định hướng trước hành động) so với sensors (feedback, quan sát sau hành động).
- Kiến trúc permission và safety. Permissive (nhanh nhưng rủi ro, tự động phê duyệt hầu hết hành động) so với restrictive (an toàn nhưng chậm, yêu cầu phê duyệt cho từng hành động). Lựa chọn phụ thuộc vào bối cảnh triển khai.
- Chiến lược tool scoping. Nhiều tool thường đồng nghĩa với hiệu suất kém hơn. Vercel loại bỏ 80% tools khỏi v0 và đạt kết quả tốt hơn. Claude Code đạt được giảm 95% context qua lazy loading. Nguyên tắc: chỉ expose tập tool tối thiểu cần thiết cho bước hiện tại.
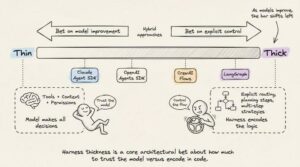
- Độ dày của harness. Bao nhiêu logic nằm trong harness so với model. Anthropic đặt cược vào thin harness và cải tiến model. Các framework dựa trên graph đặt cược vào explicit control. Anthropic thường xuyên xóa các bước planning khỏi harness của Claude Code khi các phiên bản model mới nội tại hóa năng lực đó.
Harness Chính Là Sản Phẩm
Hai sản phẩm dùng model giống hệt nhau có thể có hiệu suất khác nhau hoàn toàn chỉ dựa trên thiết kế harness. Bằng chứng từ TerminalBench rất rõ ràng: chỉ thay đổi harness đã dịch chuyển các agent hơn 20 hạng.
Harness không phải là bài toán đã được giải hoặc một tầng commodity. Đó là nơi công việc kỹ thuật khó nhất tồn tại: quản lý context như một tài nguyên khan hiếm, thiết kế verification loop để bắt lỗi trước khi chúng tích lũy, xây dựng memory system cung cấp tính liên tục mà không ảo giác, và đặt cược kiến trúc về bao nhiêu scaffolding cần xây so với bao nhiêu để lại cho model.
Lĩnh vực đang tiến dần về phía các harness mỏng hơn khi model ngày càng cải thiện. Nhưng bản thân harness sẽ không biến mất. Ngay cả model có năng lực nhất cũng cần thứ gì đó để quản lý context window của nó, thực thi tool call, duy trì state, và xác minh công việc.




Vui lòng đăng nhập để bình luận.