Chào mừng trở lại
Vui lòng đăng nhập để khám phá toàn bộ các bài viết hấp dẫn tại VTI Tech Blog
Vui lòng đăng nhập để khám phá toàn bộ các bài viết hấp dẫn tại VTI Tech Blog
 (+84) 24-7303-9996
(+84) 24-7303-9996
 vti.techblog@vti.com.vn
vti.techblog@vti.com.vn
Khám phá các góc nhìn công nghệ, chia sẻ kinh nghiệm và cập nhật xu hướng mới nhất từ những người trực tiếp tạo ra giải pháp tại VTI.

Mở đầu Trong bài này chúng ta đi tìm hiểu các tạo ra định nghĩa 1 đoạn regex, bắt đầu từ các điều cơ bản nhé. Nguyên tắc chung So sánh lần lượt các kí tự liền nhau từ trái sang phải. Ví dụ: DEPTRAI tức là tìm kiếm các…

Regex cho hạng gà Mở đầu Mình định viết 1 loạt các bài về các công việc mình đang làm (đại khái liên quan tới log). Trước tiên là về Regex. Để: Sau này mình có quên thì xem lại Và cũng là cứu vớt những tâm hồn lầm lỡ…
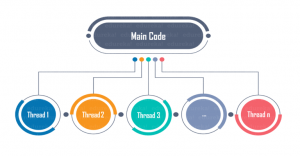
Thư viện XGBoost được thiết kế để làm việc h iệu quả với cơ chế xử lý song song trên nhiều core (multithreading) của phần cứng, cả trong quá trình train và dự đoán. Hãy cùng nhau tìm hiểu cơ chế đó thông qua bài viết này. 1. Chuẩn bị…
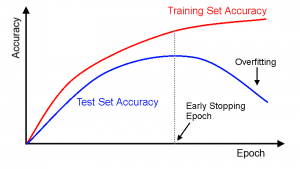
Overfitting vẫn luôn là một vấn đề làm đau đầu những kỹ sư AI. Trong bài viết này chúng ta sẽ cùng tìm hiểu cách thức monitor (giám sát) performance (hiệu năng) của XGBoost model trong suốt quá trình train. Từ đó cấu hình early stopping để quyết định khi…

Quay lại với chủ để XGBoost, hôm nay chúng ta sẽ tìm hiểu cách thức lự chọn features cho XGBoost model. Feature selection hay lựa chọn features là một bước tương đối quan trọng trước khi train XGBoost model. Lựa chọn đúng các features sẽ giúp model khái quát hóa…

Giả sử bạn đã train xong một XGBoost model đạt được độ chính xác rất cao. Câu hỏi đặt ra là làm sao lưu lại model đó để sử dụng về sau (không phải mất công train lại model mỗi khi cần sử dụng)? Trong bài viết này, chúng ta…
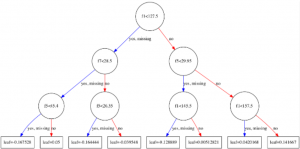
Ta đã biết, XGBoost thực chất là tập hợp gồm nhiều decision tree. Việc thể hiện mỗi decision tree đó trên đồ thì sẽ giúp chúng ta hiểu sâu sắc hơn quá trình boosting khi đưa vào một tập dữ liệu. Trong bài này, hãy cùng tìm hiểu cách thức…

Mục đích của việc phát triển mô hình dự đoán là tạo ra một mô hình có độ chính xác cao khi kiểm tra trên bộ dữ liệu độc lập với dữ liệu train (gọi là unseen data). Trong bài viết này, chúng ta cùng tìm hiểu hai phương pháp…

XGBoost là một thuật toán thuộc họ Gradient Boosting. Những ưu điểm vượt trội của nó đã được chứng minh qua các cuộc thi trên kaggle. Dữ liệu đầu vào cho XGBoost model phải ở dạng số. Nếu dữ liệu không ở dạng số thì phải được chuyển qua dạng…
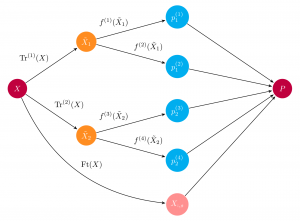
Tiếp tục phần 2 của loạt bài tìm hiểu toàn cảnh về Ensemble Learning, trong phần này ta sẽ đi qua một số thuât toán thuộc nhóm Bagging và Boosting. Các thuật toán thuộc nhóm Bagging bao gồm: Bagging meta-estimator Random forest Các thuật toán thuộc họ Boosting bao gồm:…

I. Lời nói đầu: Gần đây các hệ thống áp dụng Dev/Ops đã dần trở nên phổ biến. Các thao tác test cơ bản như unit test, integration test đã được thực hiện một cách tự động hóa hoàn toàn. Đối với từng ngôn ngữ khác nhau, chúng ta có…
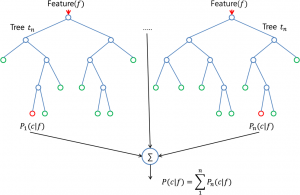
1. Giới thiệu về Ensemble Learning Giả sử chúng ta có một bài toán phân loại sản phẩm sử dụng ML. Team của bạn chia thành 3 nhóm, mỗi nhóm sử dụng một thuật toán khác nhau để train model trên tập train set. Sau đó đánh giá độ chính…


Khám phá cơ chế nhuận bút khi đóng góp bài viết ngay tại đây!
Vui lòng đăng nhập để khám phá toàn bộ các bài viết hấp dẫn tại VTI Tech Blog
