


Thư viện XGBoost được thiết kế để làm việc h iệu quả với cơ chế xử lý song song trên nhiều core (multithreading) của phần cứng, cả trong quá trình train và dự đoán. Hãy cùng nhau tìm hiểu cơ chế đó thông qua bài viết này.
1. Chuẩn bị dataset
Chúng ta sẽ sử dụng Otto Group Product Classification Challenge dataset để minh họa cơ chế multithreading của thư viện XGBoost. Để download dataset này, bạn cần đăng nhập vào Kaggle. có 2 file là train.csv và test.csv. Vì chỉ có file train.csv là có nhãn nên ta sẽ sử dụng file này. Download file train.csv về máy tính (dạng train.csv.zip). Giải nén nó ra và đặt trong thư mục làm việc của bạn.
Dataset này bao gồm khoảng 94.000 sản phẩm và 93 input featuresđược chia thành 10 nhóm (ví dụ: thời trang, điện tử, …). Mục tiêu là xây dựng một model để phân loại một sản phẩm mới vào các nhóm này. Cuộc thi này đã kết thúc vào 05/2015 và người chiến thắng cũng sử dụng XGBoost để tạo model.
2. Ảnh hưởng của số lượng threads đến thời gian train model
XGBoost được viết bằng C++, sử dụng OpenMP API để phát triển cơ chế xử lý song song. Trong một số trường hợp, bạn có thể phải compile mại XGBoost mới có thể sử dụng cơ chế song song này. Chi tiết về việc cài đặt XGBoost, có thể xem tại đây.
Hai lớp XGBClassifier và XGBRegressor trong thư viện XGBoost cung cấp tham số nthread để chỉ ra số lượng threads mà XGBoost sử dụng trong quá trình train. Mặc định thì giá trị của tham số này là -1, tức là sử dụng tất cả các core của hệ thống.
model = XGBClassifier(nthread=-1)Bây giờ chúng ta sẽ xây dựng một số XGBoost models khác nhau theo số lượng threads sử dụng và đo đặc thời gian train của mỗi model.
Code snippet:
# evaluate the effect of the number of threads
results = []
num_threads = [1, 2, 3, 4, 5, 6, 7, 8]
for n in num_threads:
start = time.time()
model = XGBClassifier(nthread=n)
model.fit(X_train, y_train)
elapsed = time.time() - start
print(n, elapsed)
results.append(elapsed)Áp dụng vào bộ dữ liệu Otto (bạn có thể thay đổi giá trị của mảng num_threads theo máy tính của bạn):
from matplotlib import pyplot
# load data
data = read_csv('test.csv')
dataset = data.values
# split data into X and y
X = dataset[:,0:94]
y = dataset[:,94]
# encode string class values as integers
label_encoded_y = LabelEncoder().fit_transform(y)
# evaluate the effect of the number of threads
results = []
num_threads = [1, 2, 3, 4]
for n in num_threads:
start = time()
model = XGBClassifier(nthread=n)
model.fit(X, label_encoded_y)
elapsed = time() - start
print(n, elapsed)
results.append(elapsed)
# plot results
pyplot.plot(num_threads, results)
pyplot.ylabel('Speed (seconds)')
pyplot.xlabel('Number of Threads')
pyplot.title('XGBoost Training Speed vs Number of Threads')
pyplot.show()Chạy code trên thu được kết quả:
1 50.13007640838623
2 26.999273538589478
3 18.629448890686035
4 15.561982154846191
5 13.940500497817993
6 12.550707578659058
7 13.075348854064941
8 12.36113166809082và đồ thị thể hiện mối quan hệ giữa số lượng threads và thời gian train model.
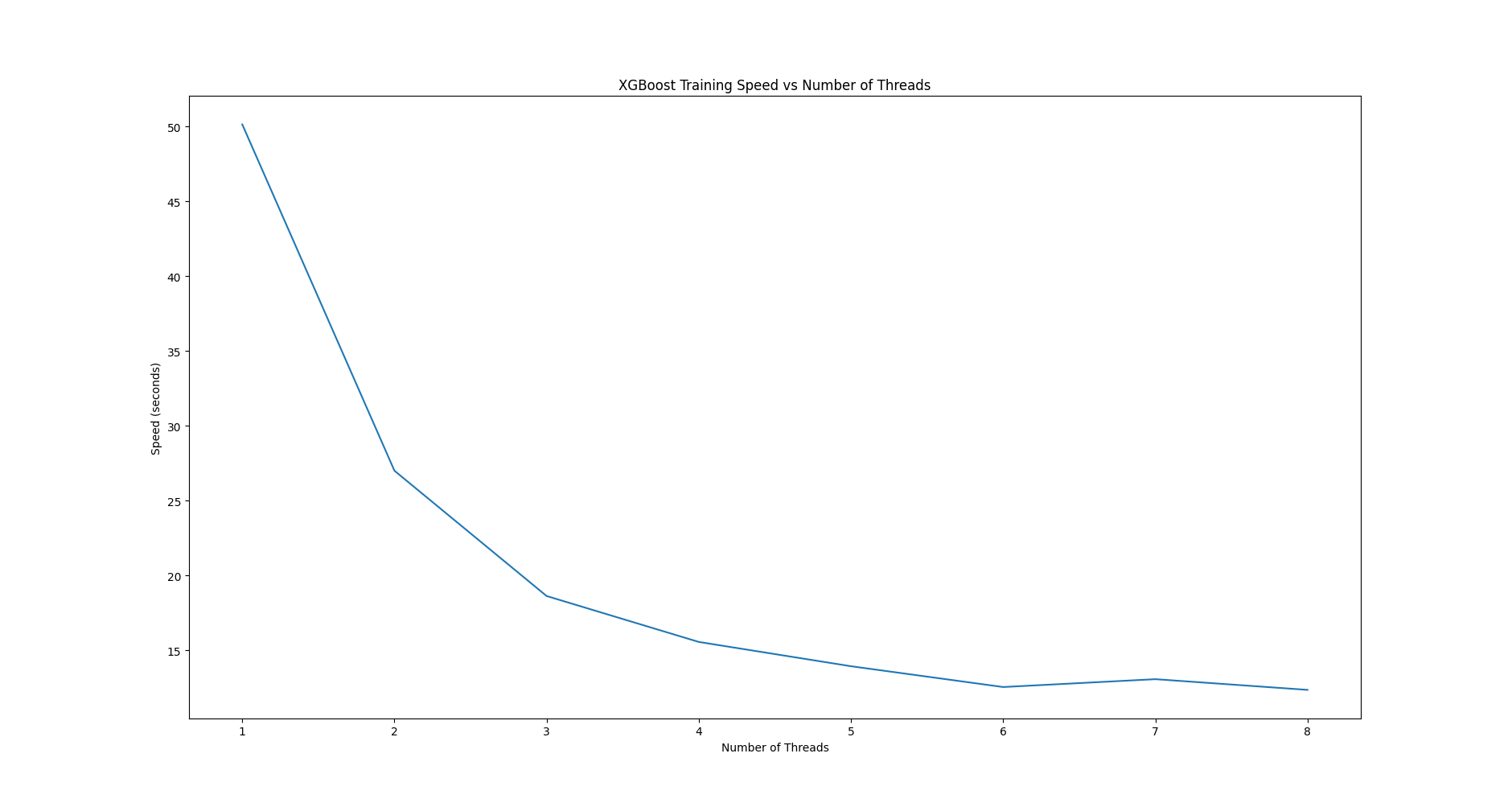
Có thể thấy rõ xu hướng giảm của thời gian train model khi số lượng threads tăng lên. Nếu kết quả chạy trên máy của bạn không giống như vậy, bạn cần phải xem xét lại cách enable cơ chế song song của XGBoost như link tham khảo mình đề cập bên trên.
3. Ảnh hưởng của số lượng threads đến thời gian cross-validation
k-fold cross-validation hỗ trợ bởi thư viện scikit-learn cũng có cơ chế xử lý song song tương tự như XGBoost. Tham số n_jobs của hàm cross_val_crore() chỉ ra số lượng threads sử dụng. Mặc định, n_jobs=1 tức là chỉ sử dụng 1 core (1 thread). Ta có thể gán giá trị -1 cho nó để sử dụng tất cả cores của hệ thống.
results = cross_val_score(model, X, label_encoded_y, cv=kfold,scoring='neg_log_loss', n_jobs=-1, verbose=1)Đến đây lại xuất hiện một câu hỏi, chúng ta nên chọn phương án nào trong 3 phương án sau:
- Disable multithreading của XGBoost, enable multithreading của cross-validation.
- Enable multithreading của XGBoost, disable multithreading của cross-validation.
- Enable multithreading của XGBoost, enable multithreading của cross-validation.
Để trả lời câu hỏi này, không gì chính xác hơn là chúng ta sẽ code cho cả 3 cách và so sánh thời gian thực thi của mỗi cách:
# Otto, parallel cross validation
from pandas import read_csv
from XGBoost import XGBClassifier
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import LabelEncoder
import time
# load data
data = read_csv('train.csv')
dataset = data.values
# split data into X and y
X = dataset[:,0:94]
y = dataset[:,94]
# encode string class values as integers
label_encoded_y = LabelEncoder().fit_transform(y)
# prepare cross validation
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7)
# Single Thread XGBoost, Parallel Thread CV
start = time.time()
model = XGBClassifier(nthread=1)
results = cross_val_score(model, X, label_encoded_y, cv=kfold, coring='neg_log_loss', n_jobs=-1)
elapsed = time.time() - start
print("Single Thread XGBoost, Parallel Thread CV: %f" % (elapsed))
# Parallel Thread XGBoost, Single Thread CV
start = time.time()
model = XGBClassifier(nthread=-1)
results = cross_val_score(model, X, label_encoded_y, cv=kfold, scoring='neg_log_loss, n_jobs=1)
elapsed = time.time() - start
print("Parallel Thread XGBoost, Single Thread CV: %f" % (elapsed))
# Parallel Thread XGBoost and CV
start = time.time()
model = XGBClassifier(nthread=-1)
results = cross_val_score(model, X, label_encoded_y, cv=kfold, scoring='neg_log_loss', n_jobs=-1)
elapsed = time.time() - start
print("Parallel Thread XGBoost and CV: %f" % (elapsed))Kết quả cuối cùng:
Single Thread XGBoost, Parallel Thread CV: 101.820478
Parallel Thread XGBoost, Single Thread CV: 455.847770
Parallel Thread XGBoost and CV: 98.794466Rõ ràng, phương án thứ 3 sử dụng thời gian ít nhất. Bây giờ bạn đã biết câu trả lời rồi phải không? 😀
4. Kết luận
Trong bài viết này, chúng ta đã tìm hiểu cách cấu hình cơ chế multithreading của XGBoost model. Chúng ta cũng nhận thức được ảnh hưởng của số lượng threads (số lượng cores) đến thời gian train model, từ đó biết cách kiểm tra xem hệ thống có hỗ trợ cơ chế xử lý song song của XGBoost hay không? Cuối cùng, cách cấu hình tốt nhất cho cả XGBoost và cross-validation để giảm thời gian thực thi cũng đã được tìm ra.
Ở bài viết tiếp theo chúng ta sẽ tìm hiểu cách scale-up XGBoost model để sử dụng nhiều cores của hệ thống hơn trên AWS cloud. Hãy cùng đón đọc! 🙂
Toàn bộ source code của bài này các bạn có thể tham khảo trên github cá nhân của mình tại github.
Tham khảo bài viết gốc tại đây.




Vui lòng đăng nhập để bình luận.