


Chào mọi người, lại là mình, SuNT đến từ team AI VTI-VN!
Gần 3 năm trước, mình có tham gia học/thi để lấy chứng chỉ IBM Data Science Professional Certificate do IBM cấp thông qua nền tảng học trực tuyến Coursera. Người tham gia phải học đủ 9 courses xoay quanh các kiến thức về Data Science (bây giờ số lượng courses đã tăng lên 10). Cuối mỗi courses là các bài tập về kiểm tra, mà người học phải làm và gửi lên hệ thống để được chấm điểm. Đặc biệt là courses cuối cùng, đó là một dạng bài tập lớn, một dự án tổng hợp, áp dụng các kiến thức đã được học trong suốt quá trình (Capstone Project) để giải quyết một dự án Data Science trong thực tế. Nếu vượt qua được dự án này thì người học sẽ được cấp chứng chỉ chuyên gia Data Science của IBM. Nếu bạn quan tâm có thể tìm hiểu và học tại đây.
Trong bài này mình sẽ trình bày về dự án đó của mình để chia sẻ cùng mọi người!
1. Định nghĩa vấn đề cần giải quyết
Theo báo cáo xếp hạng chỉ số kinh tế toàn cầu, Nhật Bản hiện đang là nước đứng thứ 3, chỉ sau Mỹ và Trung Quốc. Tokyo, nơi mà mình may mắn có dịp được sống và làm việc trong gần 2 năm (2017-2018), cũng là một trong những thành phố hiện đại và năng động nhất trên thế giới. Vì thế, sẽ không có gì ngạc nhiên khi ngày càng có nhiều doanh nhân, nhà đầu tư chọn Tokyo là điểm đến lý tưởng cho các dự án đầy tham vọng của mình. Nếu bạn cũng là một người trong số đó, hay thậm chí chỉ đơn giản là muốn mở một start up business nhỏ nhỏ của mình thì bài viết này có thể hữu ích cho bạn.
Nói đến Tokyo, bên cạnh những thắng cảnh du lịch nổi tiếng thì mình ấn tượng mạnh với văn hóa ẩm thực tại đó. Các nhà hàng Sushi, Rame, Udon, … hay các quán Bar, Pub, … các của hàng Caffe, … luôn chật kín người vào thời gian nghỉ trong ngày. Bạn cũng không cần phải bỏ ra một số tiền quá lớn để có thể thưởng thức các món ăn đặc sắc ở đây. Một bữa trưa văn phòng, theo mình nhớ thì có giá tầm 500-1000 Yên (hoặc có thể do mình ít tiền nên chọn quán rẻ tiền). Sẽ là một ý tưởng không tồi nếu bạn muốn mở một nhà hàng tại Tokyo để phục vụ các món ăn ngon cho khách hàng. Theo thống kê, tỷ suất lợi nhuận cho một nhà hàng kinh doanh tốt dao động trong khoảng 15-20%. Thậm chí có thể lên đến 30% vào các dịp đặc biệt trong năm, như báo cáo tại đây.
Về mặt địa lý, Tokyo bao gồm 23 quận đặc biệt – special wards – 東京都区部, trong đó có 7 quận được coi là Business Wards gồm — Chiyoda (千代田区), Chuo (中央区), Shinjuku (新宿区), Shibuya (渋谷区), Shinagawa (品川区), Minato (港区), và Meguro (目黒区) vì sự sầm uất trong kinh doan buôn bán của nó. Chúng ta sẽ tập trung vào phân tích số liệu của 7 quận đó trong bài này.
Tóm lại, vấn đề cần giải quyết trong bài này là: Tìm ra một địa điểm thích hợp để mở một nhà hàng mới tại Tokyo.
Nội dung bài viết bao gồm các phần:
- Chuẩn bị dữ liệu
- Phân tích dữ liệu
- Kết luận (trả lời vấn đề nêu ra ở trên)
Không giống như bài trước, khi mà chúng ta đã có sẵn dataset, trong bài này, chúng ta phải tự đi cào dữ liệu từ trên Internet về để phân tích.
2. Đối tượng độc giả hướng đến
Nội dung của bài viết này sẽ phù hợp với những nhóm độc giả sau:
- Những người làm kinh doanh và đang quan tâm đến việc đầu tư hoặc mở một nhà hàng mới tại Tokyo.
- Những người đang muốn tìm các nhà hàng, quán xá vui chơi, ăn uống, nghỉ ngơi gần nhà, công ty của họ.
- Những người đang muốn trở thành một Data Scientist, bởi vì sẽ có rất nhiều kỹ thuật chuẩn bị, phân tích, đánh giá dữ liệu được sử dụng trong bài này.
3. Data Preparation
3.1 Tìm thông tin địa lý về các quận của Tokyo
Thông tin địa lý của 23 quận thuộc thành phố Tokyo được cung cấp tại địa chỉ Special Wards of Tokyo trên Wikipedia. Các thông tin này ở dạng bảng nên ta có thể dễ dàng lấy về bằng 2 thư viện request và Beautifulsoup4.
# get html table code
response_obj = requests.get('https://en.wikipedia.org/wiki/Special_wards_of_Tokyo').text
soup = BeautifulSoup(response_obj,'lxml')
tko_wards_table = soup.find('table', {'class':'wikitable sortable'})Sau một vài thao tác biến đổi thì ta có được thông tin về diện tích, dân số, các khu phố chính như sau:
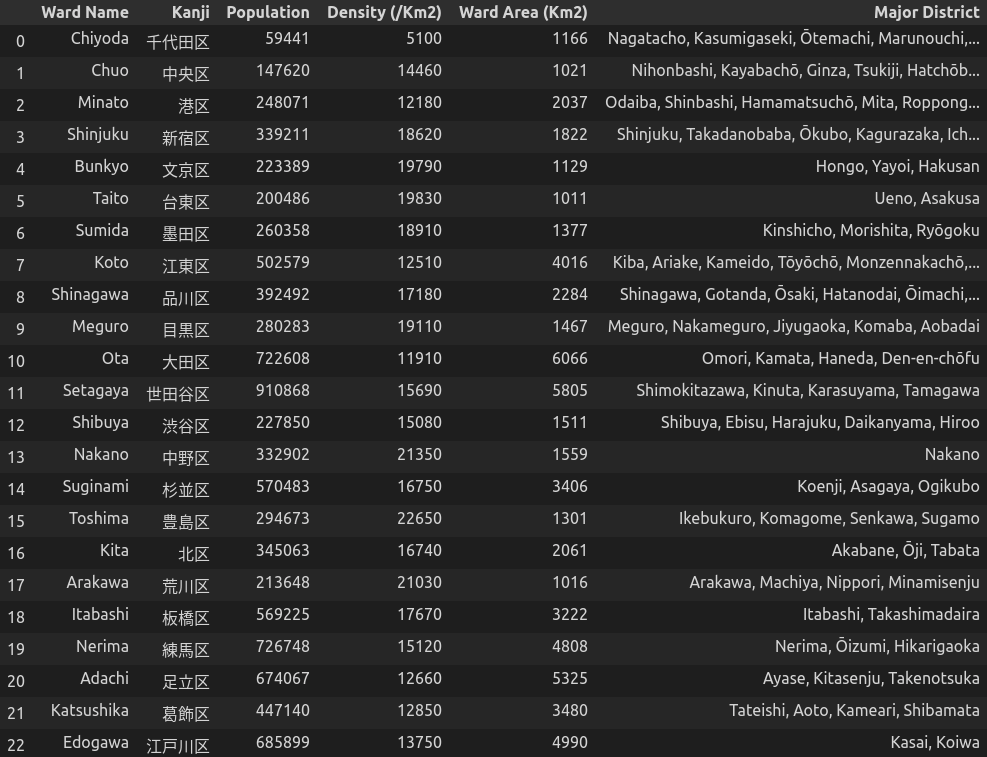
Tiếp theo, ta sẽ lấy thông tin kinh độ và vĩ độ của từng quận, sử dụng thư viện Geophy.
# get latitude & longitude of major districts
geolocator = Nominatim(user_agent='Tokyo_Explorer')
df_tko['Ward Coord'] = df_tko['Ward Name'].apply(geolocator.geocode).apply(lambda x: (x.latitude, x.longitude))
# separate latitude & longtitude into 2 different columns
df_tko[['Ward Latitude', 'Ward Longtitude']] = df_tko['Ward Coord'].apply(pd.Series)
df_tko.drop(['Ward Coord'], axis=1, inplace=True)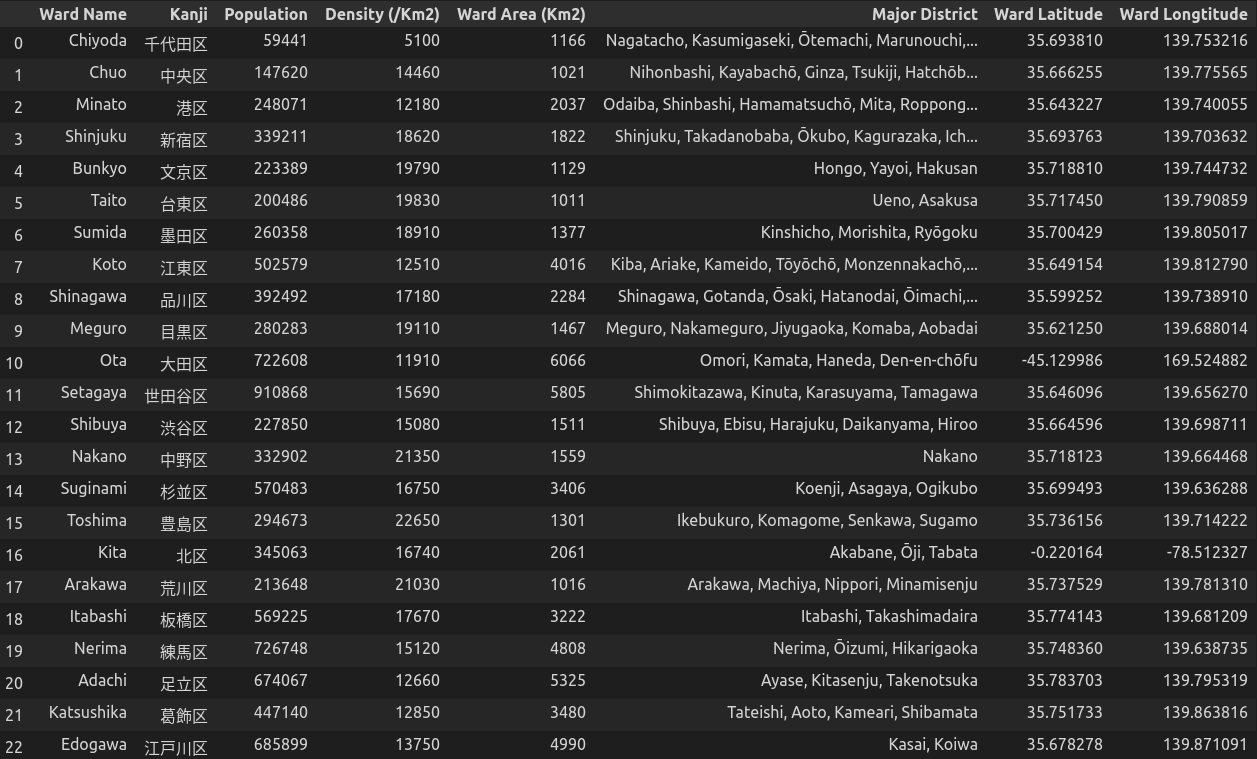
Chú ý là một số tên quận có cách viết khác so với bình thường (VD: Chūō, Bunkyō, …). Ta phải sửa lại cho đúng để có thể lấy được chính xác tọa độ của chúng như kết quả trong bảng trên.
3.2 Tìm thông tin về giá đất tại mỗi quận
Giá đất tại mỗi quận cũng là một yếu tố quan trọng để quyết định nơi sẽ đặt nhà hàng mới. Do đó, ta sẽ lấy thêm thông tin này để phân tích từ trang thông tin tổng hợp land market value area in Tokyo. Nó cũng ở dạng bảng nên ta vẫn dùng hai thư viện requests và Beautifulsoup4 để cào về.
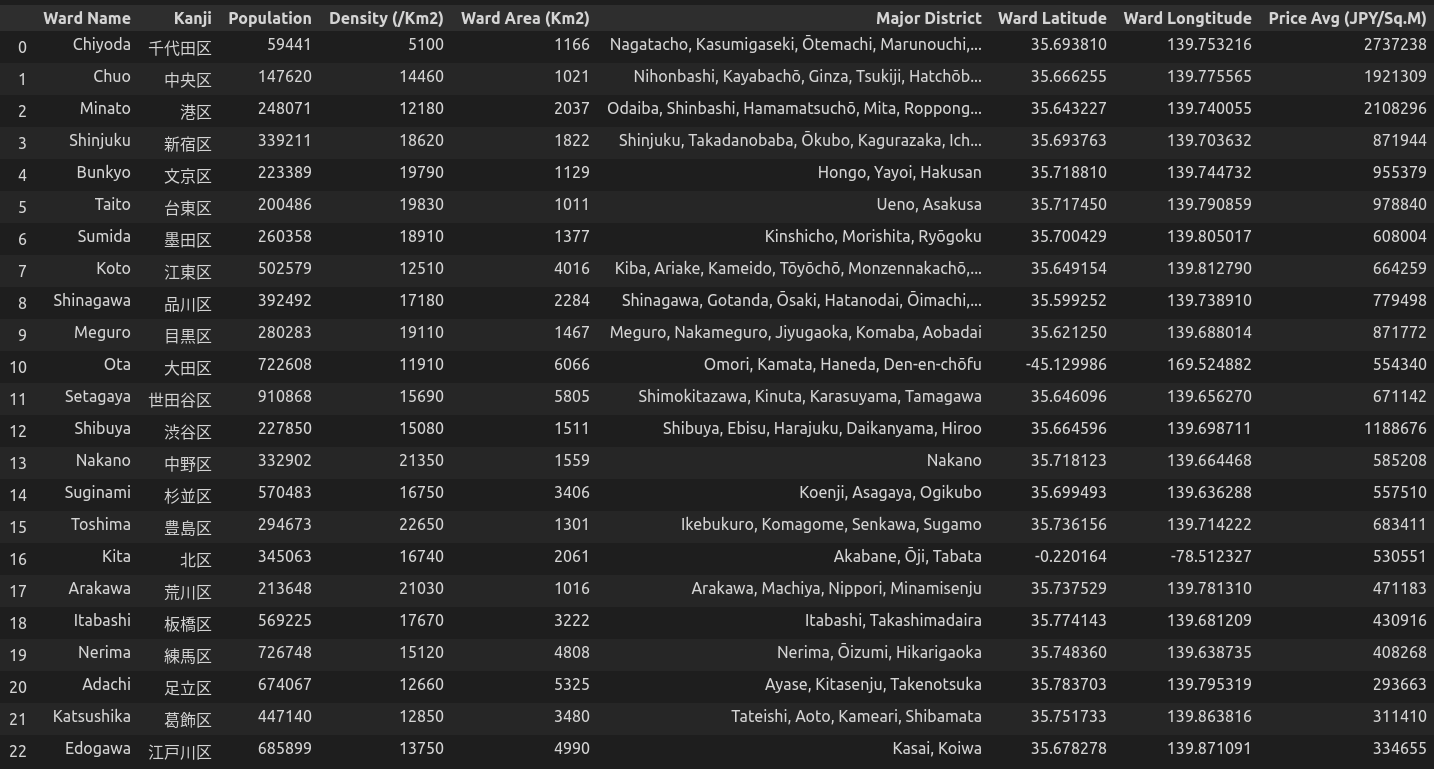
Bạn có thể lưu lại các thông tin đã có vào file csv để dễ dàng sử dụng về sau.
3.3 Chọn ra 7 quận để tiến hành phân tích
Như đã trình bày trong phần đặt vấn đề bên trên, chúng ta sẽ chỉ tập trung vào 7 business wards để phân tích trong bài này.
business_wards = ['Chiyoda', 'Chuo', 'Minato', 'Shinjuku', 'Shibuya', 'Shinagawa', 'Meguro']
df_tko_spe = df_tko.loc[df_tko['Ward Name'].isin(business_wards)].reset_index(drop=True)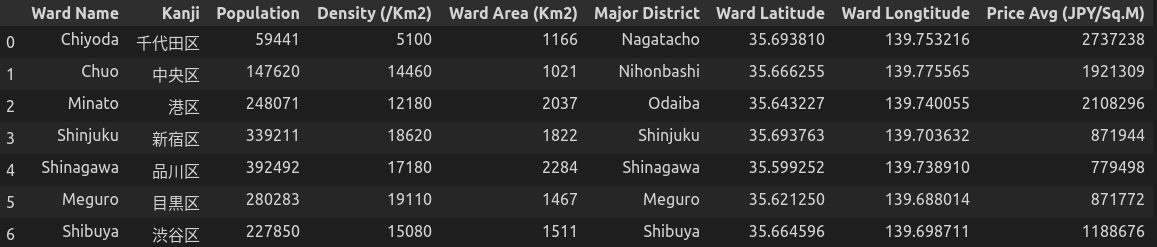
3.4 Tìm thông tin về các địa điểm của từng quận
Có thể bạn đã biết, Foursquare là mạng xã hội chia sẻ địa điểm hàng đầu trên thế giới. Trên đó có tương đối đầy đủ các địa điểm được chi sẻ bởi người dùng khắp nơi trên thế giới. Các địa điểm được phân chia thành các nhóm liên quan đến nhau để người dùng có thể dễ dàng tìm kiếm.
Đối với các nhà phát triển, Foursquare cung cấp các API để cho các ứng dụng gọi đến và trả về danh sách các địa điểm dựa vào tọa độ được cung cấp. Để sử dụng được các API này, bạn phải đăng ký tài khoản, và lựa chọn một trong 3 gói dịch vụ của Foursquare.
Sau khi thành công đang kí tài khoản và tạo dự án trên Foursquare thì chúng ta sẽ được cung cấp 2 thông tin là CLIENT_ID và SECRET_ID để sử dụng khi gọi API. API sử dụng trong bài này Venue Recommendation. Khi gọi API để lấy danh sách địa điểm mong muốn, chúng ta có thể đưa thêm các điều kiện như phạm vi tìm kiếm, số lượng tối đa, … và còn rất nhiều tham số khác để giúp ta lấy được các địa điểm sát với mong muốn hơn.
# function to get venues from foursquare through foursquare API
def getVenues(latitude, longitude, radius=1000):
venues_100_list = []
for lat, long in zip(latitude, longitude):
url = 'https://api.foursquare.com/v2/venues/explore?&client_id={}&client_secret={}&v={}&ll={},{}&radius={}&limit={}'.format(
CLIENT_ID, CLIENT_SECRET, VERSION, lat, long, radius, limit)
result = requests.get(url).json()['response']['groups'][0]['items']
venues_100_list.append(result)
return venues_100_listỞ đây, ta chọn 100 địa điểm trong vòng bán kính 1km của mỗi quận. Kết quả trả về dưới dạng Json, sau khi bóc tách ra các thông tin cần thiết thì ta được như sau:

Như vậy là ta đã có đầy đủ dữ liệu. Mình cũng đã kiểm tra, dữ liệu mà ta cào từ trên Internet về tương đối chuẩn, không bị thiếu. Mặc dù có một vài sai sót nhỏ nhưng mình cũng đã chỉnh sửa luôn trong quá trình chuẩn bị gì liệu bên trên nên ta có thể tiến hành phân tích luôn mà không cần qua bước làm sạch dữ liệu.
4. Explore Data Analysis
4.1 So sánh diện tích giữa các quận
# draw pie chart
fig = px.pie(df_tko_spe,
values=df_tko_spe['Ward Area (Km2)'],
names=df_tko_spe['Ward Name'],
title='Percentage in area of 23 wards Tokyo',
color_discrete_sequence=px.colors.sequential.Rainbow)
fig.update_layout(margin=dict(t=10, b=10, l=0, r=0))
fig.show()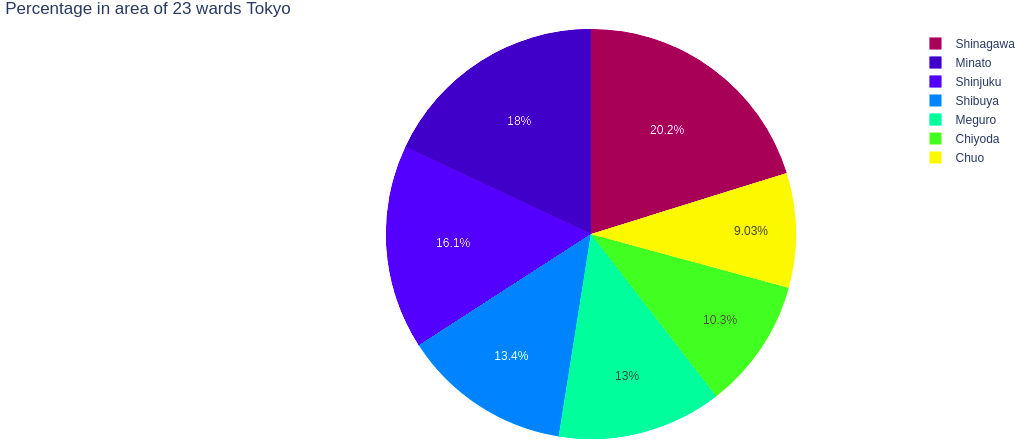
Xét về diện tích thì quận lớn nhất là Shinagawa và quận nhỏ nhất là Chuo. Nếu giả sử Tokyo chỉ bao gồm 7 quận như đang xét thì 20.2% và 9.03% là phần trăm tương ứng mà Shinagawa và Chuo chiếm của Tokyo. Hai quận Shinjuku và Shibuya xếp ở vị trí thứ 3 và 4 với 16.1% và 13.4%.
4.2 So sánh dân số và mật độ dân cư
# draw group bar chart
fig = go.Figure(
data=[
go.Bar(name="Density", x=df_tko_spe['Ward Name'], y=df_tko_spe['Density (/Km2)'], text=df_tko_spe['Density (/Km2)'], textposition='auto'),
go.Bar(name="Population", x=df_tko_spe['Ward Name'], y=df_tko_spe['Population'], text=df_tko_spe['Population'], textposition='auto'),
],
layout=go.Layout(title="Compare population and density of 7 wards",
yaxis_title="Value", xaxis_title="Wards")
)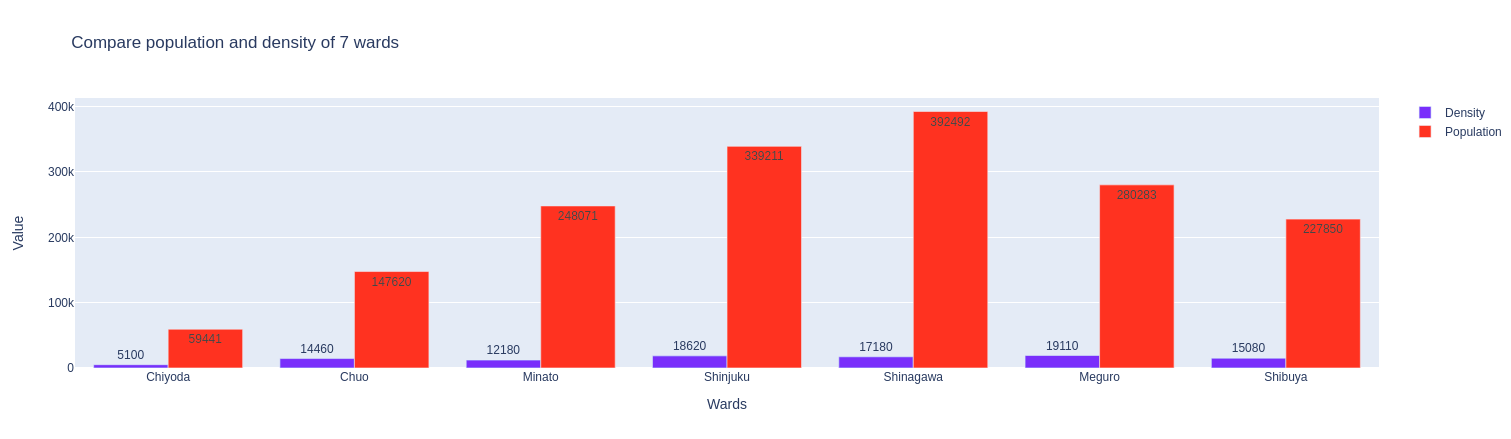
Xét về dân số thì Shinagawa vẫn là quận đứng đầu với gần 400 nghìn người. Tiếp đến là Shinjuku và Meguro, … Quận có dân số ít nhất là Chiyoda với chỉ gần 60 nghìn người.
Xét về mật độ dân số, không ngoài dự tính khi Shinagawa có con số cao nhất, 2284 người/$Km^2$. Chiyoda và Chuo xấp xỉ nhau ở vị trí cuối cùng với các con số tương ứng là 1166 người/$Km^2$ và 1021 người/$Km^2$. Shinjuku và Shibuya là 2 quận khá nổi tiếng về mức độ sầm uất với các hoạt động vui chơi, giải trí hết sức hoành tráng nên không có gì ngạc nhiên khi mật độ dân số của chúng khá cao, 1862 người/$Km^2$ và 15080 người/$Km^2$.
4.3 So sánh giá đất trung bình của các quận
# draw bar chart
fig = px.bar(df_tko_spe,
x='Ward Name',
y='Price Avg (JPY/Sq.M)',
color='Price Avg (JPY/Sq.M)',
title="Average of land price in Tokyo",
labels={'Ward Name': 'Wards', 'Price Avg (JPY/Sq.M)': 'Average Land Price ((JPY/Sq.M)'},
text='Price Avg (JPY/Sq.M)'
)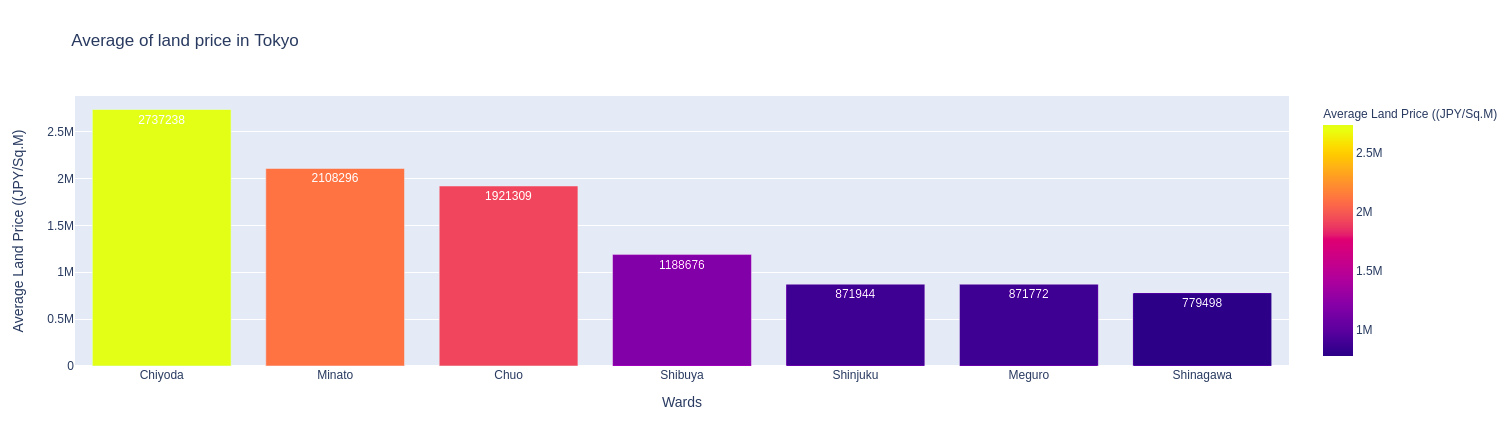
Quận có giá đất đắt đỏ nhất là Chiyoda với gần 2.8 triệu Yên/$Km^2$, và Shinagawa là quận rẻ nhất, chỉ khoảng 78 Man Yên/$Km^2$. Chắc có lẽ vì Shinagawa có nhiều đất quá, :D. Các vị trí tiếp theo sau vị trí đứng đầu là Minato, Chuo, Shibuya, Shinjuku, và Meguro.
4.4 Hiển thị vị trí của các quận lên bản đồ
# create map of Tokyo with 5 major districts are displayed
tko_map = folium.Map(location=[tko_lat, tko_lng], zoom_start=12)
for lat, long, label in zip(df_tko_spe['Ward Latitude'], df_tko_spe['Ward Longtitude'], df_tko_spe['Ward Name']):
label = folium.Popup(label, parser_html=True)
folium.CircleMarker(
[lat, long],
radius=20,
popup=label,
color='magenta',
fill=True,
fill_color='#3186cc',
fill_opacity=0.7
).add_to(tko_map)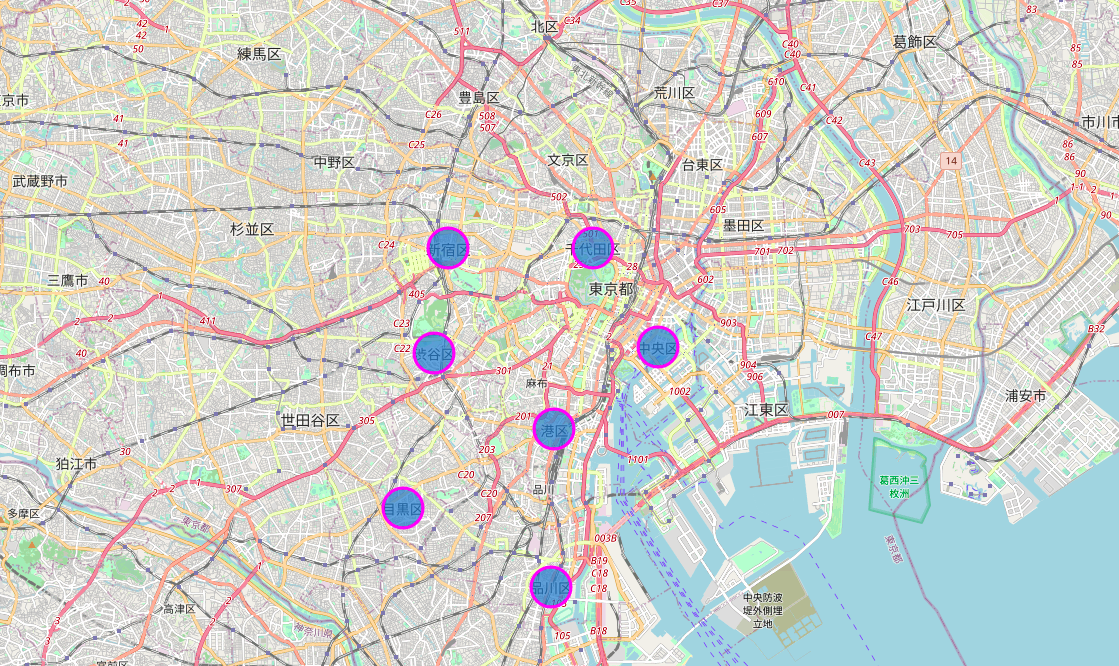
4.5 Thống kê 10 nhóm địa điểm phổ biến nhất tất cả các quận
# statistic top 10 categories
df_tko_venues_top10 = df_tko_venues['Venue Category'].value_counts()[0:10].to_frame(name='Frequency').reset_index()
df_tko_venues_top10.rename(index=str, columns={'index':'Venue Category'}, inplace=True)
# draw bar chart
fig = px.bar(df_tko_venues_top10,
x='Venue Category',
y='Frequency',
color='Frequency',
title="Top 10 Most Frequency Occuring Venues in 7 wards of Tokyo",
labels={'Venue Category': 'Venues Category'},
text='Frequency'
)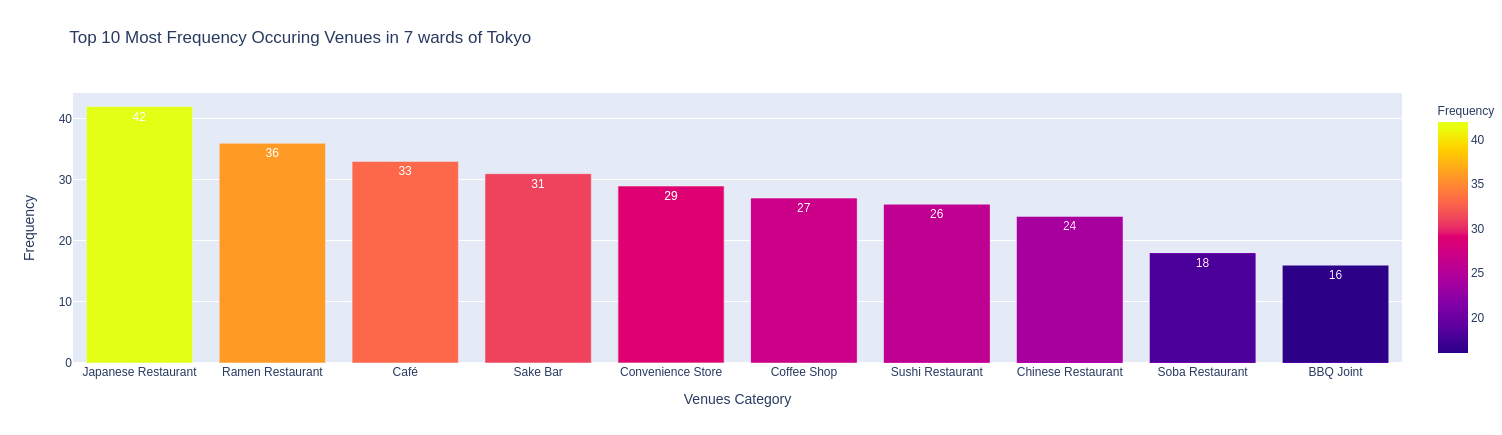
Xét về tổng thể, các nhà hàng kiểu/món Nhật chiếm đa số, tất nhiên rồi, vì đây là đất nước Nhật Bản mà. Tiếp theo là Ramen, một món ăn quá quen thuộc của người dân Nhật Bản. Hơi ngạc nhiên là nhà hàng Sushi không thấy xuất hiện trong danh sách này.

4.6 Thống kê nhóm 5 địa điểm phổ biến tại mỗi quận
# display top 5 venues common of each ward in bar charts
for df_top5 in df_tko_venues_top5_list:
# draw bar chart
fig = px.bar(df_top5[1],
x='Venue Category',
y='Frequency Score',
color='Frequency Score',
title="Top 5 Most Frequency Occuring Venues in {} wards of Tokyo".format(df_top5[0]),
labels={'Venue Category': 'Venues Category', 'Frequency Score':'Frequency Score'},
text='Frequency Score'
)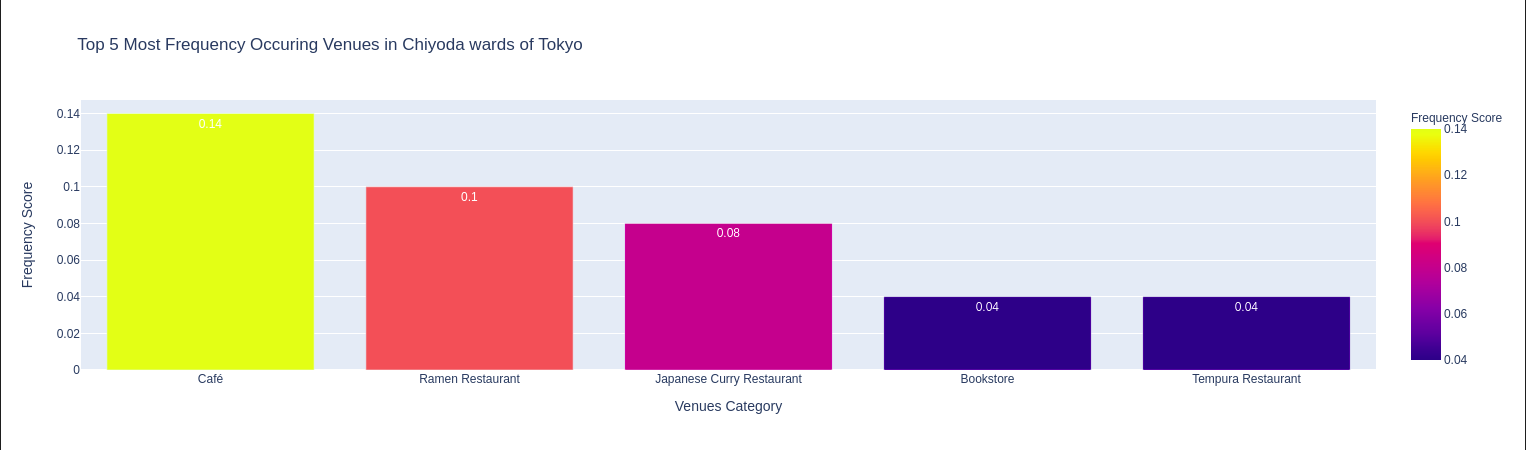
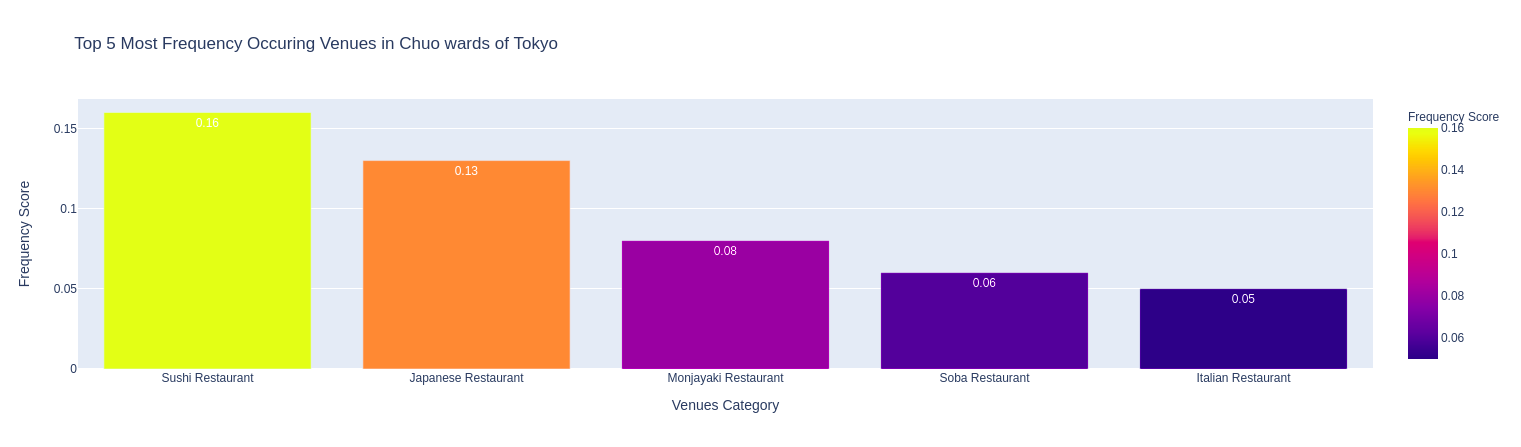
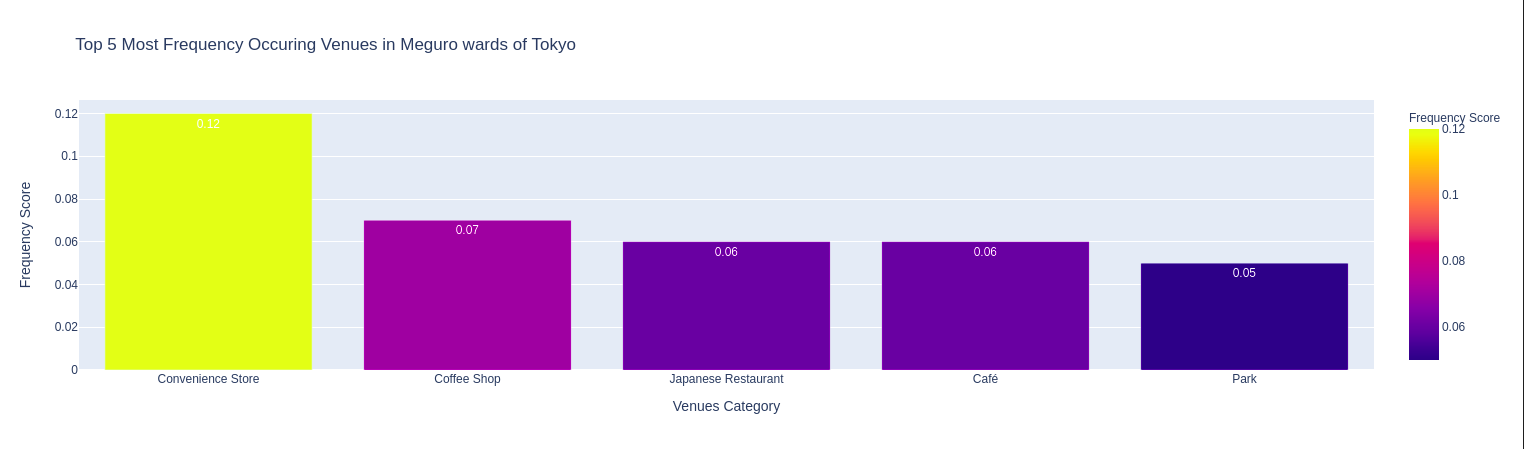
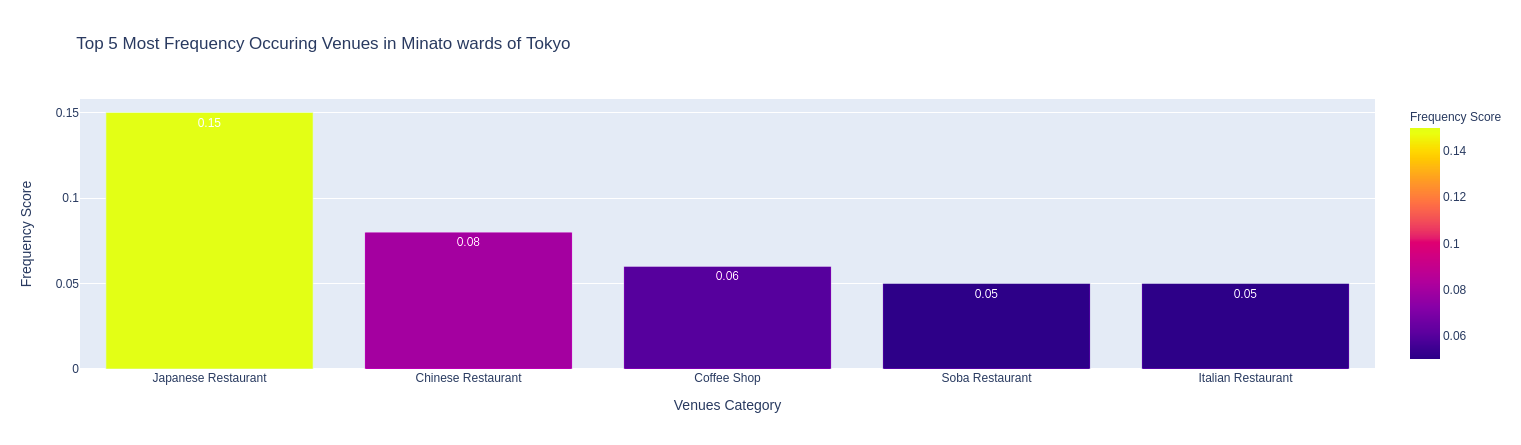
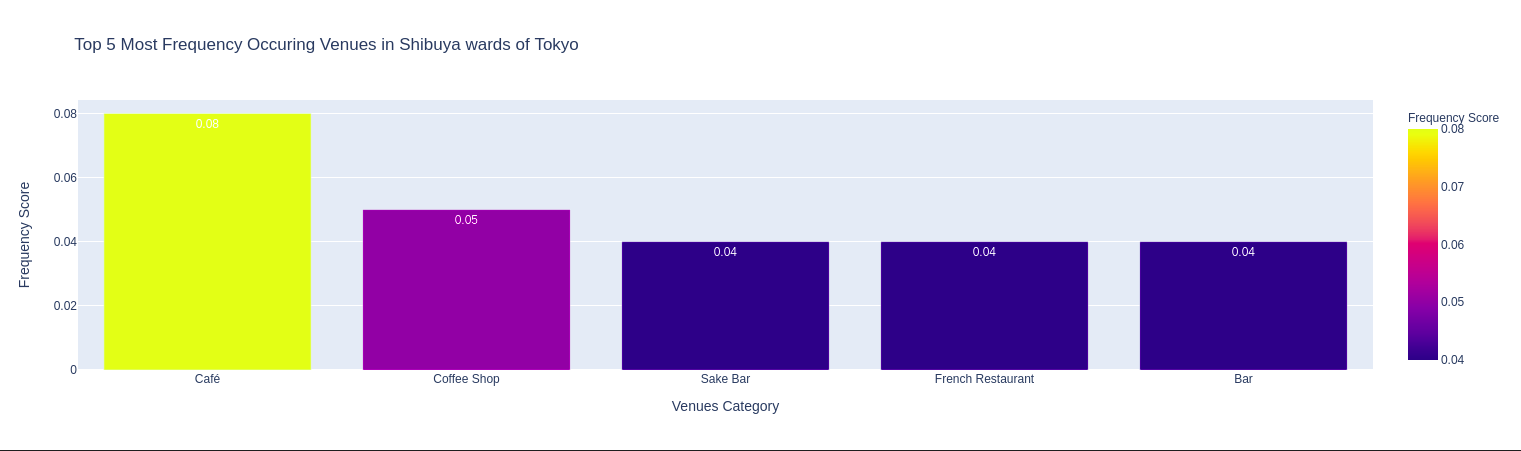
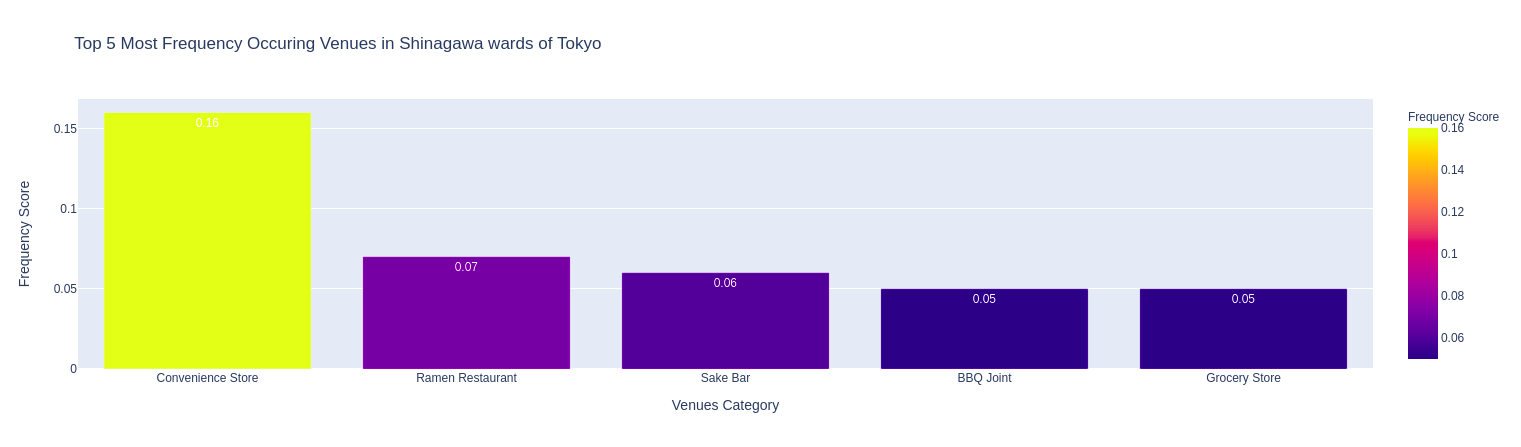
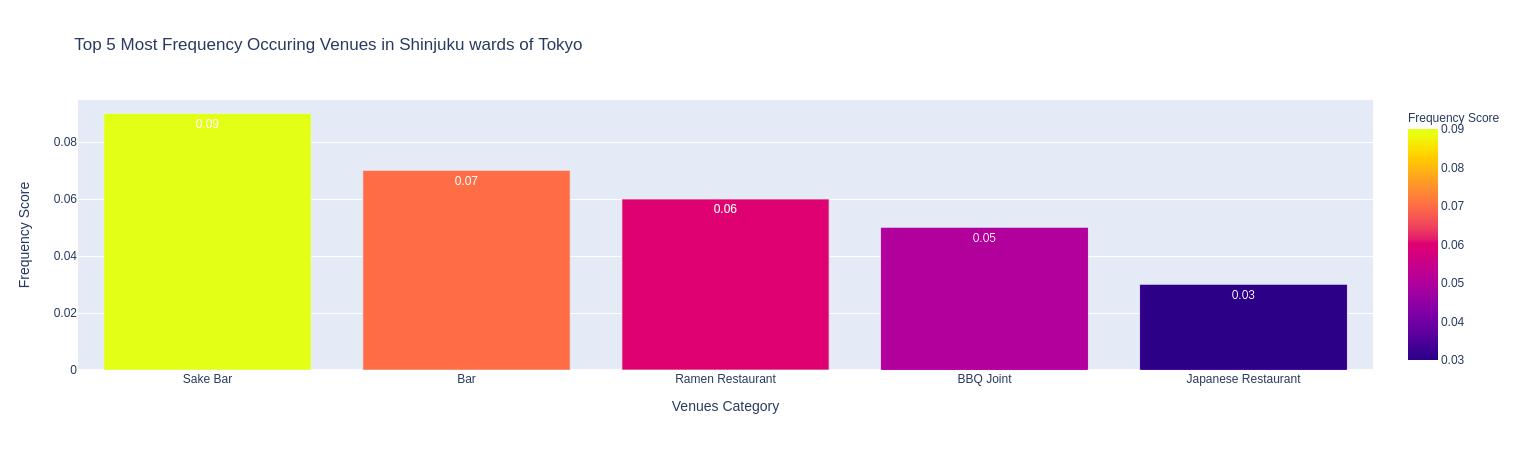
Caffe (2), Sushi, Convenience Store (2), Sake Bar, Japanese Restaurant là những nhóm địa điểm đứng đầu về mức độ phổ biến trong các quận. Ngoài ra còn có nhà hàng Tempura, các nhà hàng món ăn nước ngoài (Chinese, Italian, French, …), nhà hàng BBQ, nhà hàng Ramen, nhà hàng Soba, Book Store, …
Bởi vì ta đang quan tâm đến việc mở nhà hàng mới, nên mình sẽ thu gọn lại chỉ xem xét nhóm địa điểm nhà hàng.
4.7 Thống kê số lượng nhà hàng ở mỗi quận
Có nhiều cách để thể hiện số lượng nhà hàng của mỗi quận. Ở đây mình giới thiệu 3 cách cho các bạn tham khảo.
- Cách thứ nhất: Sử dụng đồ thị dạng Bar
df_tko_venues_rest = df_tko_venues[df_tko_venues['Venue Category'].str.contains('Restaurant')]
df_tko_venues_rest = df_tko_venues_rest.reset_index(drop=True)
...
fig = px.bar(df_tko_venues_rest_count,
# x='District',
x='Ward Name',
y='Number of Rest',
color='Number of Rest',
title="Number of Restaurants in each Ward",
labels={'Ward Name': 'Ward', 'Number of Rest':'Number of Restaurant'},
text='Number of Rest'
)
Cách thứ 2: Sử dụng bản đồ HeadMap, màu càng đậm thì số lượng nhà hàng càng lớn và ngược lại.
hm_data = df_tko_venues_rest_count[['Ward Latitude', 'Ward Longtitude', 'Number of Rest']]
hm_data = hm_data.values.tolist()
# hm_data[:5]
hmap = folium.Map(location=[tko_lat, tko_lng], control_scale=True, attr='USGS style', zoom_start=5)
HeatMap(hm_data, rasdius=10).add_to(hmap)
# hmap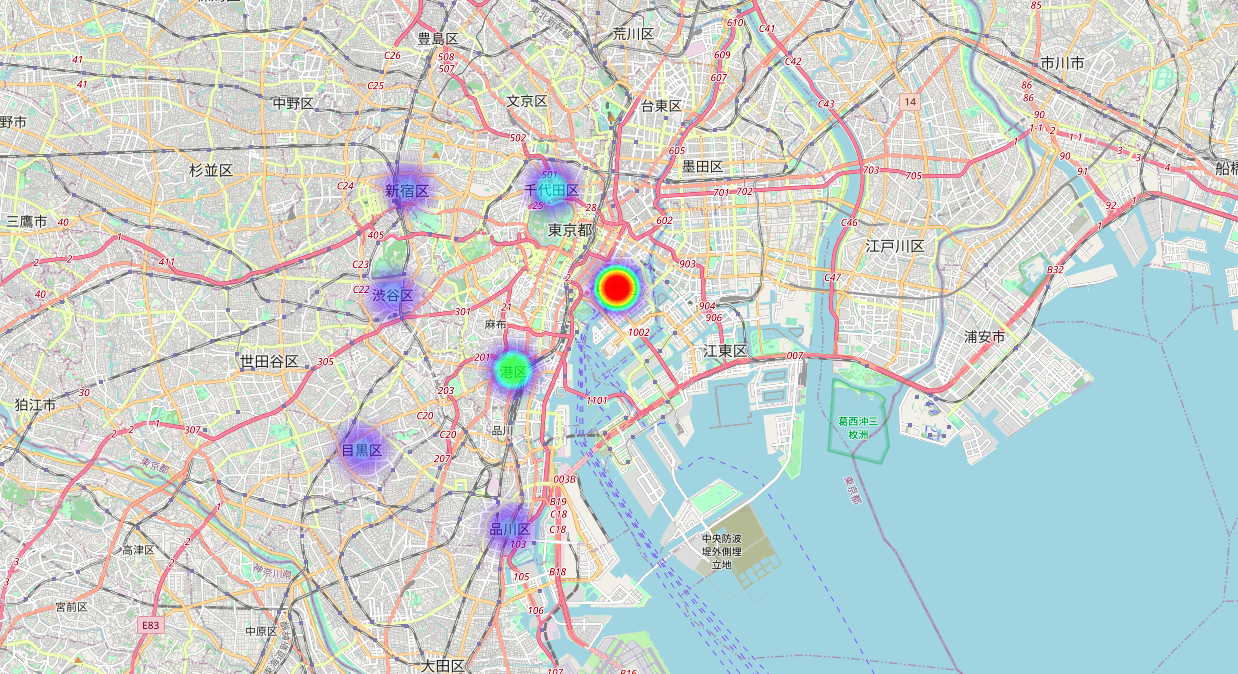
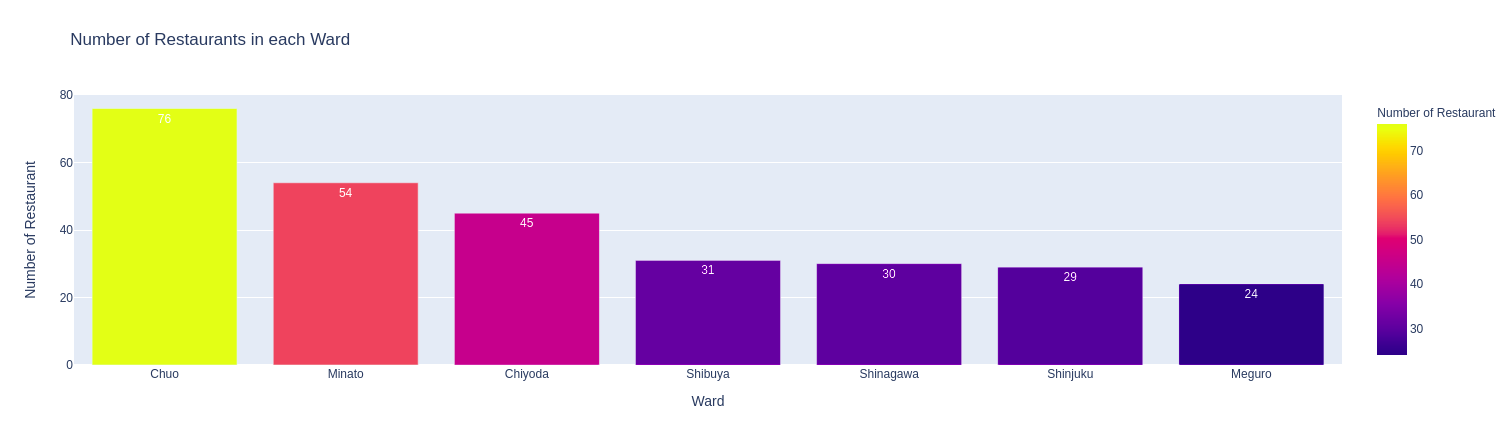
Trong vòng 1 Km từ trung tâm thì Chuo là quận có số nhà hàng nhiều nhất, 76. Tiếp đó là Minato, Chiyoda lần lượt là 54 và 45. 3 quận Shibuya, Shinagawa, và Shinjuku có số lượng nhà hàng xấp xỉ nhau (31, 30, 29). Đứng ở vị trí thấp nhất là Meguro, chỉ có 24 nhà hàng.
Cách thứ 3: Sử dụng bản đồ kết hợp với CircleMarker. Bán kính của CirleMarker càng lớn thì số lượng nhà hàng càng nhiều và ngược lại.
for lat, lon, poi, cluster in zip(df_tko_spe_all['Ward Latitude'],
df_tko_spe_all['Ward Longtitude'],
df_tko_spe_all['Ward Name'],
df_tko_spe_all['Cluster ID']):
label = folium.Popup(str(poi) + ' Cluster ' + str(cluster), parse_html=True)
folium.CircleMarker(
[lat, lon],
radius=n_rest[wards.index(poi)]*0.5,
popup=label,
color=rainbow[cluster-1],
fill=True,
fill_color=rainbow[cluster-1],
fill_opacity=0.7).add_to(map_clusters)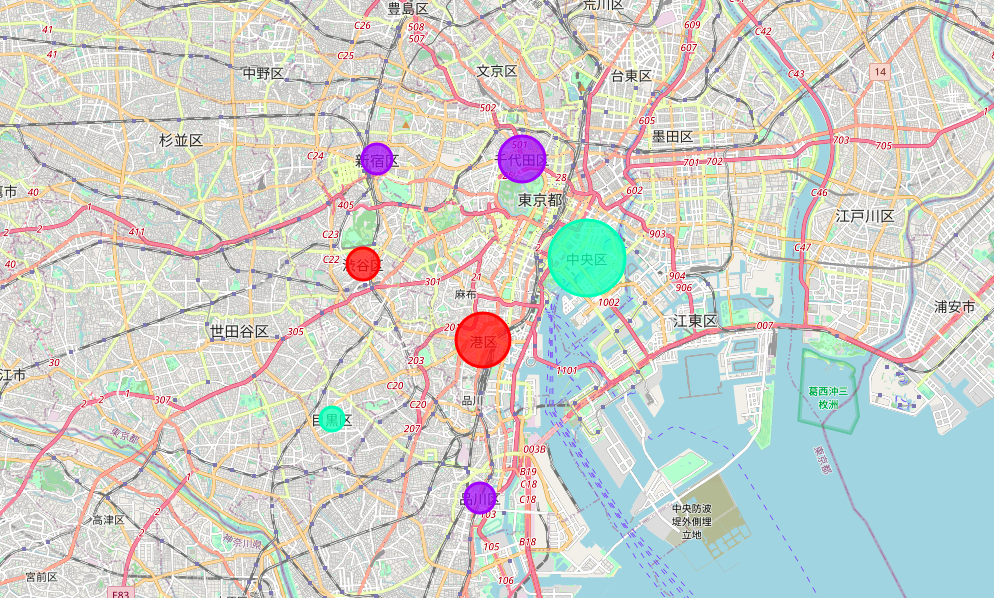
Cách thể hiện số 2&3 còn cho ta biết cụ thể vị trí của mỗi quận trên bản đồ địa lý.
Ngoài ra, ở cách số 3, mình cũng đưa thêm một thông tin nữa, đó là việc phân cụm các quận thành 3 cụm khác nhau dựa trên mức độ tương tự giữa các nhóm địa điểm của mỗi quận. Theo đó thì Shibuya và Minato thuộc cụm số 1 (màu đỏ), Shinjuku, Chiyoda và Shinagawa thuộc cụm số 2 (màu tím). Cuối cùng là Chuo và Meguro thuộc cụm số 3 (màu xanh).
5. Tổng kết và đánh giá
Theo như toàn bộ phân tích trên thì Shinagawa chắc chắc sẽ là nơi tiềm năng để bắt đầu một business mới, bởi vì:
- Giá đất của Shinagawa rẻ nhất so với các quận khác.
- Dân số của Shinagawa đông nhất so với các quận khác.
- Hiện nay, số lượng nhà hàng tại Shinagawa còn khá khiêm tốn, Convenience Store đang chiếm đa số tại đây.
Do vậy, nếu bạn mở nhà hàng tại đây thì sẽ ít phải cạnh tranh với các đối thủ khác so với các quận còn lại.
6. Thảo luận
Những phân tích và đánh giá trên đây mới chỉ đề cập đến một vài khía cạnh nhỏ của bài toán thực tế và còn nhiều hạn chê:
- Dữ liệu phụ thuộc vào Foursquare (đây là một nền tảng chia sẻ thông tin địa điểm của người dùng nên thông tin có thể chưa thực sự chính xác)
- Số lượng quận đươc đem ra phân tích ở đây mới là 7.
- Số lượng địa điểm và phạm vi tìm kiếm địa điểm vẫn còn hạn chế (100 địa điểm trong vòng 1km)
-
Chưa xét đến các yếu tố khác như: lịch sử, văn hóa, giao thông, …
Mặc dù vậy, những phân tích này vẫn rất có giá trị trong việc làm thông tin tham khảo và mở ra những hướng phân tích mới khi triển khai vào thực tế.
7. Kết luận
Theo thiết kế của IBM thì nếu người học dành ra khoảng 3h/tuần để học thì sẽ hoàn thành chương trình này trong 11 tháng. Mình thì tập trung học nên mất gần 2 tháng để có được chứng chỉ.

Mình nghĩ đây là 1 chương trình học rất bổ ích và cần thiết cho những người muốn theo đuổi con đường trở thành một Data Scientist. Đặc biệt là Capstone Project, không dễ dàng để vượt qua nó nhưng khi đã làm được rồi thì cảm giác rất phấn khích. Như kiểu mình đã trở thành một Data Scientist thực thụ rồi, 😀
Toàn bộ code của bài này, các bạn có thể tham khảo tại đây.
8. Tham khảo
[1] SuNT, "Khám phá thành phố Tokyo xinh đẹp", Available online: https://tiensu.github.io/blog/105_eda_explore_tokyo/ (Accessed on 28 Aug 2021).




Vui lòng đăng nhập để bình luận.