


Chào mọi người, lại là mình, SuNT đến từ team AI VTI-VN!
Hưởng ứng lời kêu gọi toàn dân sáng tác thơ, chào mừng sinh nhật 4 năm của công ty, do chị Chung phát động, mình cũng muốn tham gia nhưng mà nghĩ mãi chẳng ra câu thơ nào. Thôi thì đành nhờ anh bạn AI giúp đỡ vậy.
Công ty công nghệ IT
Thu nay 4 tuổi, có gì bạn ơi?
Dự án lớn, nhỏ khắp nơi
Nhân tài khắp chốn đều bơi về cùng
Công nghệ sẵn có tinh thông
Thêm trình quản lý vừa thâm vừa dầy
Về cùng chung sức dựng xây
Cơ đồ sự nghiệp lẫy lừng vẻ vang
Dù gian khó, vẫn vững vàng
Từng bước phát triển ngày càng phồn vinh
VTI, mãi bên mình
Sắt son lời hứa, vẹn tình không phai!Có thể bạn đã biết về AI và những ứng dụng của nó trong nhiều lĩnh vực của cuộc sống: Y tế, giáo dục, giao thông, nông nghiệp, công nghiệp, … Nhưng liệu bạn có biết là AI còn tham gia vào cả các lĩnh vực mà đòi hỏi sự sáng tạo của con người như sáng tác thơ, nhạc, truyện, vẽ tranh, … những việc tưởng chừng như không thể thay thế được của con người?
Trong bài này, mình sẽ cùng các bạn xây dựng một model AI đơn giản để sáng tác thơ thử xem sao ha! 😀
1. Giới thiệu mô hình Seq2Seq trong các bài toán NLP
Text Generation và Machine Translation là hai trong số các bài toán điển hình của NLP. Nếu như Text Generation có nhiệm vụ sinh ra các văn bản mới thì Machine Translation lại chịu trách nhiệm dịch văn bản từ một ngôn ngữ gốc sang các ngôn ngữ khác nhau. Ví dụ, từ tiếng Việt sang tiếng Nhật, từ tiếng Việt sang tiếng Anh, … Cả 2 bài toán này đều có một đặc điểm chung là nhận dữ liệu đầu vào là một chuỗi các từ (input sequence) và sinh ra một chuỗi các từ khác (target sequence). Chính vì thế mà kiến trúc mô hình để giải quyết các dạng bài toán như thế này được gọi là Seq2Seq.
Mô hình Seq2Seq được giới thiệu lần đầu vào năm 2014 bởi Google. Mục đích của nó là ánh xạ một Input Sequence Data thành một Output Sequence Data. Chiều dài của 2 Sequence Data không nhất thiết phải giống nhau. Ví dụ khi dịch câu có 5 từ What are you doing now? từ tiếng Anh sang câu có 7 ký tự 今天你在做什麼? trong tiếng Trung Quốc.
Ngoài hai bài toán kể trên thì mô hình Seq2Seq còn có thể giải quyết các bài toán sau:
- Text Summarization – Đây là bài toán tóm tắt nội dung của một văn bản dài thành một đoạn văn bản ngắn hơn. Kể từ khi được Google giới thiệu năm 2014, nó đã trở nên khá phổ biến.
- Machine Translation – Dịch văn bản giữa các ngôn ngữ khác nhau. Google Translate chính là một sản phẩm của bài toán này.
- Image/Video Captioning – Đưa cho máy tính một bức ảnh hoặc một video, nó sẽ trả lại cho bạn một (hoặc một vài) câu miêu tả nội dung của bức ảnh / Video đó. Mình đang nghĩ rằng phần thi đầu tiên của kỳ thi TOEIC (phần thi miêu tả tranh) có thể chính là một ứng dụng thực tế của bài toán này.
- Speech Recognition – Bài toán trong lĩnh vực Audio, còn được gọi là Speech To Text, tức chuyển đổi âm thanh thành văn bản.
- Music Generation – Đây là một bài toán rất thú vị, máy tính có thể sáng tác nhạc cho bạn. Nghe chắc sẽ rất ngầu! 😀
- Recommendation Engine – Hệ thống khuyến nghị có lẽ đã không còn xa lạ với mọi người. Có rất nhiều các để tạo ra nó, và mô hình Seq2Seq với kiến trúc Encoder-Decoder cũng là một trong số đó, cho kết quả rất khả quan.
- Chatbot – Hay còn gọi là hệ thống Question-Answer. Siri hay Alexa là ví dụ thực tế.
Về kiến trúc, mô hình Seq2Seq bao gồm 2 thành phần: Encoder và Decoder. Mỗi một thành phần bao gồm nhiều NN Layers xếp chồng lên nhau (stack). NN Layer có thể là CNN, RNN, LSTM. GRU, …

- Encoder làm nhiệm vụ mã hóa các Input Sequences thành các vectors trong miền không gian đa chiều (Latent Space). Mỗi vectors này được gọi là Internal State của Input Sequence tuơng ứng.
- Decoder làm nhiệm vụ chuyển đổi các Internal States sang các Target Sequences.
Chi tiết hơn về mô hình Seq2Seq, cách làm việc cũng như hạn chế và cách khác phục hạn chế của nó, mời các bạn tham khảo trong bài viết của mình tại đây. Còn ở bài này, mình chỉ tập trung vào phần thực hành thôi.
2. Chuẩn bị dữ liệu
Bất kỳ bài toán AI nào cũng vậy, dữ liệu là yếu tố quyết định lớn đến sự thành công. Để huấn luyện mô hình làm thơ, mình sẽ sử dụng các câu thơ trong tác phẩm Truyện Kiều của đại thi hào dân tộc Nguyễn Du.

Copy toàn bộ phần nội dung của Truyện Kiều tại đây hoặc một nơi nào đó tùy bạn, vào file tên là truyenkieu.txt. Có 2 phiên bản của Truyện Kiều, bản Kinh có 3258 câu, bản Phường có 3254 câu. Mình không nhớ là copy ở đâu về nhưng của mình là bản Kinh. Bạn sử dụng bản nào cũng được vì số lượng chỉ hơn kém nhau 2 câu, không đáng kể.
2.1 Đọc dữ liệu
Trước tiên, chúng ta sẽ đọc vào dữ liệu vừa copy về để bắt đầu quá trình xử lý.
with open('truyenkieu.txt','r') as f:
data = f.read()
# separate data sentence by sentence and remove blank sentences
data_list = [line for line in data.split('\n') if line != '']
# display 10 first sentences
data_list[:10]
---
['01.Trăm năm trong cõi người ta,',
'Chữ tài chữ mệnh khéo là ghét nhau.',
'Trải qua một cuộc bể dâu,',
'Những điều trông thấy mà đau đớn lòng.',
'Lạ gì bỉ sắc tư phong,',
'Trời xanh quen thói má hồng đánh ghen.',
'Cảo thơm lần giở trước đèn,',
'Phong tình có lục còn truyền sử xanh.',
'Rằng năm Gia Tĩnh triều Minh,',
'Bốn phương phẳng lặng, hai kinh vững vàng.']2.2 Làm sạch dữ liệu
Có thể quan sát thấy dữ liệu còn đang rất bẩn, lộn xộn, chúng ta cần phải làm sạch trước khi đưa cho model để học. Một số bước tiền xử lý làm sạch dữ liệu như sau:
a, Chuyển chữ hoa thành chữ thường
data_list = [x.lower() for x in data_list]
data_list[:10]
---
['01.trăm năm trong cõi người ta,',
'chữ tài chữ mệnh khéo là ghét nhau.',
'trải qua một cuộc bể dâu,',
'những điều trông thấy mà đau đớn lòng.',
'lạ gì bỉ sắc tư phong,',
'trời xanh quen thói má hồng đánh ghen.',
'cảo thơm lần giở trước đèn,',
'phong tình có lục còn truyền sử xanh.',
'rằng năm gia tĩnh triều minh,',
'bốn phương phẳng lặng, hai kinh vững vàng.']b, Loại bỏ dấu câu
remove_digits = str.maketrans('', '', string.digits)
removed_digits_text = []
for sent in tk_text_:
sentance = [w.translate(remove_digits) for w in sent.split(' ')]
removed_digits_text.append(' '.join(sentance))
tk_text_ = removed_digits_text
tk_text_[:10]
---
['01trăm năm trong cõi người ta',
'chữ tài chữ mệnh khéo là ghét nhau',
'trải qua một cuộc bể dâu',
'những điều trông thấy mà đau đớn lòng',
'lạ gì bỉ sắc tư phong',
'trời xanh quen thói má hồng đánh ghen',
'cảo thơm lần giở trước đèn',
'phong tình có lục còn truyền sử xanh',
'rằng năm gia tĩnh triều minh',
'bốn phương phẳng lặng hai kinh vững vàng']c, Loại bỏ số
remove_digits = str.maketrans('', '', string.digits)
removed_digits_text = []
for sent in tk_text_:
sentance = [w.translate(remove_digits) for w in sent.split(' ')]
removed_digits_text.append(' '.join(sentance))
tk_text_ = removed_digits_text
tk_text_[:10]
---
['trăm năm trong cõi người ta',
'chữ tài chữ mệnh khéo là ghét nhau',
'trải qua một cuộc bể dâu',
'những điều trông thấy mà đau đớn lòng',
'lạ gì bỉ sắc tư phong',
'trời xanh quen thói má hồng đánh ghen',
'cảo thơm lần giở trước đèn',
'phong tình có lục còn truyền sử xanh',
'rằng năm gia tĩnh triều minh',
'bốn phương phẳng lặng hai kinh vững vàng']d, Loại bỏ khoảng trắng đầu và cuối mỗi câu
# removing the starting and ending whitespaces
tk_text_ = [x.strip() for x in tk_text_]
tk_text_[:10]
---
['trăm năm trong cõi người ta',
'chữ tài chữ mệnh khéo là ghét nhau',
'trải qua một cuộc bể dâu',
'những điều trông thấy mà đau đớn lòng',
'lạ gì bỉ sắc tư phong',
'trời xanh quen thói má hồng đánh ghen',
'cảo thơm lần giở trước đèn',
'phong tình có lục còn truyền sử xanh',
'rằng năm gia tĩnh triều minh',
'bốn phương phẳng lặng hai kinh vững vàng']e, Kiểm tra hiện tượng 2 câu nằm cùng 1 dòng
Lỗi này thường xuất hiện do lỗi copy Truyện Kiều từ trên website về file txt.
# check to see if there is 2 sentences are same line
for ins in tk_text_:
if len(ins.split()) > 8:
print(ins)Nếu thấy có dòng nào được in ra thì chúng ta tìm đến dòng đó để sửa trong file truyenkieu.txt.
2.3 Chuẩn bị dữ liệu
a, Chia dữ liệu thành Input/Target Sequences
Chúng ta sẽ chia 3258 câu thơ thành 2 phần:
- Input Sentenses: là những câu có 6 từ.
- Target Sentences: là những câu có 8 từ.
# create pair of input/output sequence
input_sentences, target_sentences = [], []
for index, seq_txt in enumerate(tk_text_):
if index%2 == 0:
input_sentences.append(seq_txt)
else:
target_sentences.append(seq_txt)
print(len(input_sentences), len(target_sentences))
---
(1629, 1629)Ngoài ra, theo cách hoạt động của mô hình Seq2Seq, mỗi Target Sentence cần được thêm token báo hiệu bắt đầu và kết thúc.
# add start and end token to target sequences
target_sentences = ['start '+ ts + ' end' for ts in target_sentences]b, Thực hiện Tokenize đối với Input/Target Sentences
Các mô hình AI chỉ làm việc với dữ liệu ở dạng số, vì thế chúng ta phải chuyển các Input/Target Sentences từ dạng chuỗi văn bản sang dạng số tuơng ứng. Mình sẽ sử dụng lớp Tokenizer() của thư viện Keras để làm việc này.
- Input Sentences
Xây dựng bộ từ điển (vocabulary):
# prepare the tokenizer on the input sentence
input_tokenizer = Tokenizer()
input_tokenizer.fit_on_texts(input_sentences)
---
Input Vocabulary Size: 1866Thực hiện Tokenize:
# perform tokenize on input setences
input_seq = input_tokenizer.texts_to_sequences(input_sentences)
max_len_input_seq = max([len(seq) for seq in input_seq])
input_seq = pad_sequences(input_seq, maxlen=max_len_input_seq, padding='pre')
input_seq[:10]
---
array([[ 183, 102, 13, 665, 6, 64],
[ 865, 125, 2, 538, 152, 453],
[ 103, 274, 866, 167, 275, 104],
[1183, 666, 126, 276, 41, 277],
[ 1, 102, 73, 867, 454, 184],
[ 7, 10, 868, 455, 246, 278],
[ 2, 667, 57, 869, 1184, 11],
[ 115, 11, 58, 539, 870, 456],
[ 87, 540, 247, 541, 318, 248],
[ 384, 153, 668, 385, 669, 319]], dtype=int32)Ngoài ra, hãy nhớ rằng bắt buộc các Input Sequences phải có độ dài bằng nhau. Vì vậy, chúng ta sẽ thêm các ký tự ‘0’ để tạo chuỗi có cùng độ dài. Điều này sẽ được thực hiện bởi pad_sequence.
- Target Sentences
Xây dựng từ điển:
# prepare the tokenizer on the target sentence
target_tokenizer = Tokenizer()
target_tokenizer.fit_on_texts(target_sentences)
---
Target Vocabulary Size: 1987Thực hiện Tokenize:
# perform tokenize on target setences
target_seq = target_tokenizer.texts_to_sequences(target_sentences)
max_len_target_seq = max([len(seq) for seq in target_seq])
target_seq = pad_sequences(target_seq, maxlen=max_len_target_seq, padding='pre')
target_seq[:10]
---
array([[ 1, 111, 137, 111, 258, 317, 9, 1304, 99, 2],
[ 1, 61, 126, 85, 46, 16, 178, 773, 8, 2],
[ 1, 48, 90, 402, 774, 354, 64, 355, 356, 2],
[ 1, 155, 26, 12, 645, 17, 646, 1305, 90, 2],
[ 1, 127, 481, 1306, 775, 49, 179, 647, 35, 2],
[ 1, 280, 776, 100, 7, 259, 259, 1307, 777, 2],
[ 1, 197, 128, 9, 111, 357, 558, 990, 280, 2],
[ 1, 559, 281, 9, 282, 231, 9, 559, 232, 2],
[ 1, 3, 5, 3, 318, 129, 358, 648, 129, 2],
[ 1, 482, 86, 198, 1308, 403, 991, 649, 992, 2]],
dtype=int32)c, Tạo Input/Output cho model
Mô hình Seq2Seq yêu cầu 2 Inputs là Encoder Input, Decoder Input và một Output là Decoder Output.
# create encoder/decoder input/output
for i, (input_text, target_text) in enumerate(zip(input_sentences, target_sentences)):
for t, word in enumerate(input_text.split()):
encoder_input_data[i, t] = input_word2index[word]
for t, word in enumerate(target_text.split()):
# decoder_target_data is ahead of decoder_input_data by one timestep
decoder_input_data[i, t] = target_word2index[word]
if t > 0:
# decoder_target_data will be ahead by one timestep
# and will not include the start character.
decoder_target_data[i, t - 1, target_word2index[word]] = 1.OK, như vậy là phần chuẩn bị dữ liệu đã xong. Chúng ta chuyển qua phần xây dựng mô hình AI.
3. Xây dựng mô hình Seq2Seq
3.1 Định nghĩa kiến trúc mô hình
Mô hình Seq2Seq thông thường có những hạn chế nhất định của nó, nên ở đây mình sẽ sử dụng thêm cơ chế Attention để tăng hiệu quả của mô hình.
Các thư viện Keras, Tensorflow hay Pytorch đều chưa chính thức tích hợp Attention (mình tin điều này sẽ xảy ra sớm thôi). Vì vậy, chúng ta sẽ sử dụng lớp Attention được xây dựng tại đây. Download nó về và đặt trong cùng thư mực dự án.
- Định nghĩa Encoder
Encoder sẽ bao gồm 1 lớp Embedding và 3 lớp LSTM xếp chồng liên tiếp nhau. Lớp Embedding làm nhiệm vụ chuyển các Input Sequences thành các Embedded Vectors sử dụng thuật toán Word2Vec hoặc GloVe.
# Encoder
encoder_inputs = Input(shape=(max_len_input_sentence,))
enc_emb = Embedding(input_vocab_size, latent_dim, trainable=True)(encoder_inputs)
#LSTM 1
encoder_lstm1 = LSTM(latent_dim, return_sequences=True, return_state=True)
encoder_output1, state_h1, state_c1 = encoder_lstm1(enc_emb)
#LSTM 2
encoder_lstm2 = LSTM(latent_dim, return_sequences=True, return_state=True)
encoder_output2, state_h2, state_c2 = encoder_lstm2(encoder_output1)
#LSTM 3
encoder_lstm3 = LSTM(latent_dim, return_state=True, return_sequences=True)
encoder_outputs, state_h, state_c= encoder_lstm3(encoder_output2) Chú ý rằng, tại các lớp LSTM cần đặt tham số return_sequences=True, return_state=True để nó trả về hidden_state và cell_state tại mỗi time_step.
- Định nghĩa Decoder
Decoder cũng gồm 1 lớp Embedding và 1 lớp LSTM.
# Set up the decoder.
decoder_inputs = Input(shape=(None,))
dec_emb_layer = Embedding(target_vocab_size, latent_dim,trainable=True)
dec_emb = dec_emb_layer(decoder_inputs)
#LSTM using encoder_states as initial state
decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True)
decoder_outputs,decoder_fwd_state, decoder_back_state = decoder_lstm(dec_emb,initial_state=[state_h, state_c]) Tuơng tự Encoder, lớp LSTM của Decoder cũng phải thiết lập 2 tham số return_sequences=True, return_state=True. Ngoài ra, trạng thái khởi tạo của Decoder được gán bằng giá trị cell_state và hidden_state của ở đầu ra của Encoder.
- Định nghĩa Attention layer
Lớp Attention được khởi tạo với 2 tham số là encoder_outputs của Encoder và decoder_outputs của Decoder.
#Attention Layer
attn_layer = AttentionLayer(name='attention_layer')
attn_out, attn_states = attn_layer([encoder_outputs, decoder_outputs]) - Kết hợp Output của Decoder và Attention
Output của Decoder và Attention được kết hợp lại thành một Output duy nhất:
# Concat attention output and decoder LSTM output
decoder_concat_input = Concatenate(axis=-1, name='concat_layer')([decoder_outputs, attn_out])- Định nghĩa TimeDistributed
Đây là lớp chịu trách nhiệm sinh ra kết quả cuối cùng của mô hình. Định nghĩa nó bằng cách sử dụng lớp TimeDistributed của Keras và truyền tham số là decoder_concat_input. Hàm softmax trả về xác suất của mỗi từ trong vocabulary. Từ nào có xác suất lớn nhất sẽ được chọn.
# Dense layer
decoder_dense = TimeDistributed(Dense(target_vocab_size, activation='softmax'))
decoder_outputs = decoder_dense(decoder_concat_input) - Mô hình đầy đủ
Kết hợp đầy đủ Input/Output của Encoder/Decoder với lớp Model của Keras, ta có được mô hình đầy đủ như sau:
# Define the model
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
model.summary()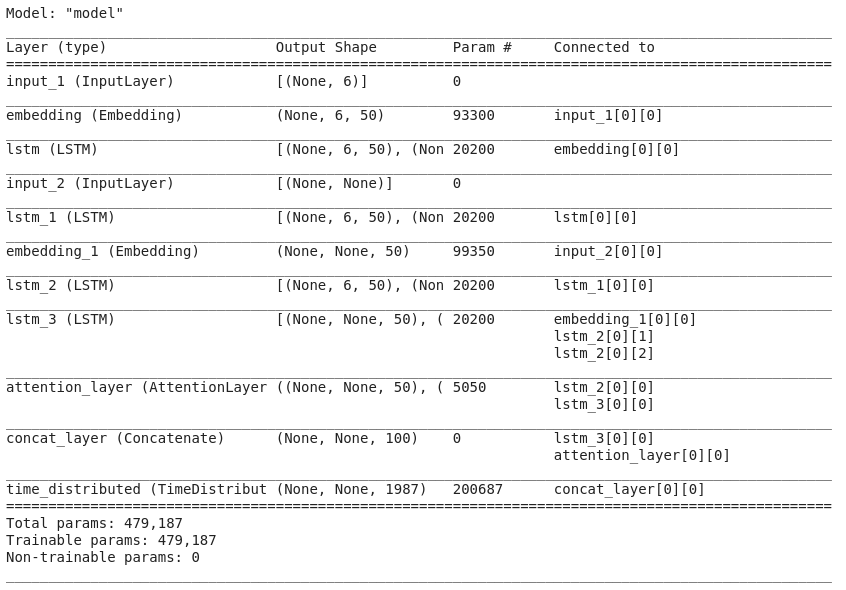
Để có cái nhìn trực quan hơn về kiến trúc thành phần và sự liên kết giữa các lớp, chúng ta sẽ thể hiện nó dưới dạng hình ảnh như dưới đây.
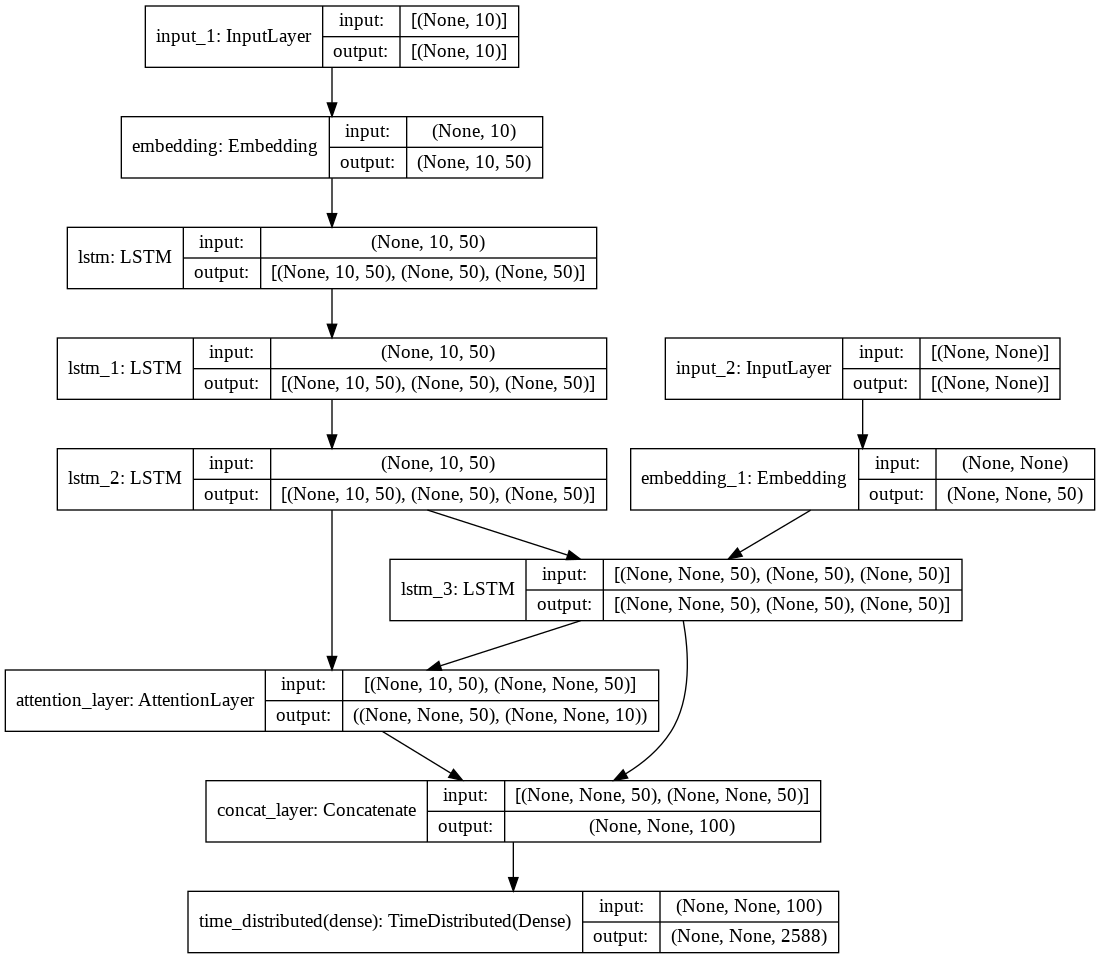
3.2 Huấn luyện mô hình
Chúng ta sẽ huấn luyện mô hình theo các tham số sau:
- x = [encoder_input_data, decoder_input_data]
- y = decoder_target_data,
- epoch: 500
- batch_size: 64
history = model.fit(
x=[encoder_input_data, decoder_input_data],
y=decoder_target_data,
batch_size=64,
epochs=500)Kết quả huấn luyện:
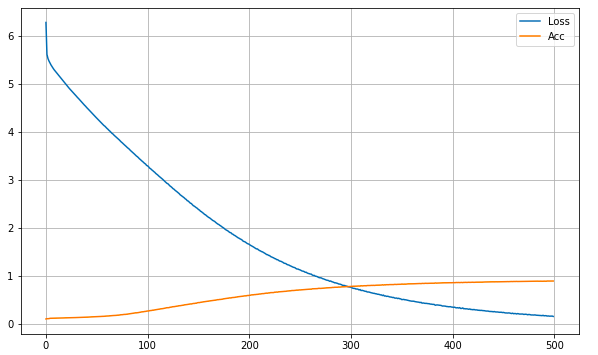
Độ chính xác đạt được là ~88.6%, loss = ~0.1482%.
3.3 Lưu mô hình
Hãy tiến hành lưu lại mô hình để
sử dụng trong tuơng lai.
model_json = model.to_json()
with open("output/PoemGen.json", "w") as json_file:
json_file.write(model_json)
# serialize weights to HDF5
model.save_weights("output/PoemGen_model_weight.h5")
print("Saved model to disk")3.4 Kiểm tra mô hình
Chúng ta sẽ thử sử dụng mô hình vừa huấn luyện để sinh ra thử một vài câu thơ xem sao. Code thực hiện như sau:
a, Load mô hình
Trước tiên, load mô hình đã được lưu trước đó:
# loading the model architecture and asigning the weights
json_file = open('output/PoemGen.json', 'r')
loaded_model_json = json_file.read()
json_file.close()
model_loaded = model_from_json(loaded_model_json, custom_objects={'AttentionLayer': AttentionLayer})
# load weights into new model
model_loaded.load_weights("output/PoemGen_model_weight.h5")b, Thực hiện Inference
# encoder inference
encoder_inputs = model_loaded.input[0] #loading encoder_inputs
encoder_outputs, state_h, state_c = model_loaded.layers[6].output #loading encoder_outputs
# print(encoder_inputs.shape)
encoder_model = Model(inputs=encoder_inputs,outputs=[encoder_outputs, state_h, state_c])
# decoder inference
# Below tensors will hold the states of the previous time step
decoder_state_input_h = Input(shape=(latent_dim,))
decoder_state_input_c = Input(shape=(latent_dim,))
decoder_hidden_state_input = Input(shape=(max_len_input_seq,latent_dim))
# Get the embeddings of the decoder sequence
decoder_inputs = model_loaded.layers[3].output
#print(decoder_inputs.shape)
dec_emb_layer = model_loaded.layers[5]
dec_emb2= dec_emb_layer(decoder_inputs)
# To predict the next word in the sequence, set the initial states to the states from the previous time step
decoder_lstm = model_loaded.layers[7]
decoder_outputs2, state_h2, state_c2 = decoder_lstm(dec_emb2, initial_state=[decoder_state_input_h, decoder_state_input_c])
#attention inference
attn_layer = model_loaded.layers[8]
attn_out_inf, attn_states_inf = attn_layer([decoder_hidden_state_input, decoder_outputs2])
concate = model_loaded.layers[9]
decoder_inf_concat = concate([decoder_outputs2, attn_out_inf])
# A dense softmax layer to generate prob dist. over the target vocabulary
decoder_dense = model_loaded.layers[10]
decoder_outputs2 = decoder_dense(decoder_inf_concat)
# Final decoder model
decoder_model = Model(
[decoder_inputs] + [decoder_hidden_state_input,decoder_state_input_h, decoder_state_input_c],
[decoder_outputs2] + [state_h2, state_c2])def decode_sequence(input_seq):
# Encode the input as state vectors.
e_out, e_h, e_c = encoder_model.predict(input_seq)
# Generate empty target sequence of length 1.
target_seq = np.zeros((1,1))
# Chose the 'start' word as the first word of the target sequence
target_seq[0, 0] = target_word2index['start']
stop_condition = False
decoded_sentence = ''
while not stop_condition:
output_tokens, h, c = decoder_model.predict([target_seq] + [e_out, e_h, e_c])
# Sample a token
sampled_token_index = np.argmax(output_tokens[0, -1, :])
if sampled_token_index == 0:
break
else:
sampled_token = target_index2word[sampled_token_index]
if(sampled_token !='end'):
decoded_sentence += ' '+ sampled_token
# Exit condition: either hit max length or find stop word.
if (sampled_token == 'end' or len(decoded_sentence.split()) >= (max_len_target_seq)):
stop_condition = True
# Update the ta`rget sequence (of length 1).
target_seq = np.zeros((1,1))
target_seq[0, 0] = sampled_token_index
# Update internal states
e_h, e_c = h, c
return decoded_sentenceThực hiện Inference với 1 vài câu thơ trong tập dữ liệu ban đầu:
for seq_index in [141, 2001, 3002]:
input_seq = encoder_input_data[seq_index: seq_index + 1]
decoded_sentence = decode_sequence(input_seq)
print('-')
print('Input sentence:', input_sentences[seq_index: seq_index + 1])
print('Decoded sentence:', decoded_sentence)
---
-
Input sentence: ['song hồ nửa khép cánh mây']
Decoded sentence: tường đông ghé mắt ngày ngày hằng trông
-
Input sentence: ['khen “tài nhả ngọc phun châu']
Decoded sentence: nàng ban ả tạ cũng đâu thế này
-
Input sentence: ['duyên hội ngộ đức cù lao']
Decoded sentence: bâng khuâng nào đã biết ai mà nhìnTa thấy câu thơ sinh ra đúng như trong bộ dữ liệu ban đầu.
Hàm sinh ra câu thơ mới dựa trên một Input Sentence người dùng nhập vào.
def make_a_poem_sentence(input_txt):
input_seq = []
for t, word in enumerate(input_txt.split()):
input_seq.append(input_word2index[word])
input_seq = np.array(input_seq)
input_seq = pad_sequences([input_seq], maxlen=max_len_input_seq, padding='pre')
decoded_txt = decode_sequence(input_seq)
print('Generated poem sentence:', decoded_txt)Kiểm tra thử kết quả:
input_txt = 'hạ về xanh biếc trên sông'
make_a_poem_sentence(input_txt)
---
Generated poem sentence: một thanh còn để mấy mùa chia trăngNghe vẻ cũng "xuôi xuôi" nhỉ! 😀
4. Hướng phát triển
Mặc dù mô hình đạt đuợc độ chính xác khá cao nhưng vẫn còn nhiều hạn chế. Một số phuơng hướng để nâng cao chất lượng của mô hình như sau:
- Thu thập thêm nhiều dữ liệu hơn nữa. Càng nhiều càng tốt.
- Sử dụng kiến trúc tiên tiến hơn, Transformer chẳng hạn.
- Sử dụng Dropout và một số phuơng pháp Regularization để giảm Overfitting.
- Thực hiện Hyper-parameter Tuning: learning rate, batch size, … Sử dụng Bidirectional LSTM thay vì LSTM, sử dụng thêm nhiều lớp LSTM, …
- Sử dụng Beam Search thay vì Greedy Search.
5. Kết luận
Vậy là chúng ta vừa cùng nhau hoàn thành xây dựng một AI model để giúp chúng ta có thể tạo ra được nhưng câu thơ hay, thú vị. Hi vọng bạn có thể học được một chút gì đó từ bài viết này của mình.
Mô hình vẫn còn nhiều hạn chế cần cải thiện để có thể sử dụng được trong thực tế. Nếu bạn có hứng thú, có thể liên hệ với mình để cùng nhau tiếp tục phát triển thêm.
Và cuối cùng, mình bật mí rằng bài thơ ở phần đầu bài viết này là sản phẩm của sự kết hợp giữa AI và con người, chứ không phải hoàn toàn bằng AI đâu nhé! Để AI có thể sáng tác được một bài thơ "mượt mà" như thế chắc sẽ cần phải làm thêm nhiều việc nữa. 😀
Cảm ơn các bạn đã đọc bài!
6. Tham khảo
[1] SuNT, “Tìm hiểu cơ chế Attention trong mô hình Seq2Seq”, Available online: https://tiensu.github.io/blog/58_attention/ (Accessed on 30 Jul 2021).
[2] Thushan Ganegedara, “Attention in Deep Networks with Keras”, Available online: https://towardsdatascience.com/light-on-math-ml-attention-with-keras-dc8dbc1fad39 (Accessed on 30 Jul 2021).
[3] Harshil Patel, “Neural Machine Translation (NMT) with Attention Mechanism”, Available online: https://towardsdatascience.com/neural-machine-translation-nmt-with-attention-mechanism-5e59b57bd2ac (Accessed on 30 Jul 2021).




Vui lòng đăng nhập để bình luận.