


Chào mọi người tôi là Hoàng đến từ team AI VTI-VN!
Đây là bài viết đầu tiên mà tôi sẽ chia sẻ trong series Machine Learning, rất mong được sự góp ý từ mọi người.
Phụ lục:
- 1. Giới thiệu
- 2. Tổng quan về ML
- 3. Linear Regression
- 4. Lập công thức chung
- 5. Thực nghiệm với Python
- 6. Đánh giá và kết luận
- 7. Tham khảo
- 8. Lời cảm ơn
1. Giới thiệu
Ở trong bài đầu tiên thuộc series Machine Learning (ML), tôi sẽ chia sẻ tới mọi người một góc nhìn tổng quan nhất cách mà ML hoạt động cũng như trình bày một trong những thuật toán căn bản nhất mà ai học và làm về AI/ML cũng phải nắm được, đó là Linear Regression.
Vì đây là bài đầu tiên, tôi sẽ tản mạn một số câu chuyện và vấn đề xung quanh AI/ML mà có thể bạn đọc có thể hứng thú. 5 năm gần đây, cụm từ "AI – trí tuệ nhân tạo" trở nên vô cùng phổ biến đối với cả dân kĩ thuật và dân kinh tế tại Việt Nam. Nhưng thực tế, công nghệ AI đã ra đời rất lâu và được nghiên cứu vô cùng mạnh mẽ ở một số quốc gia đi đầu về công nghệ mà đặc biệt là Mỹ – nơi quy tụ rất nhiều hãng công nghệ hàng đầu thế giới. Và hiện nay, Trung Quốc đang là một trong những quốc gia đi đầu về công nghệ AI trên thế giới.
AI lần đầu tiên được công bố bởi John McCarthy, một nhà khoa học máy tính Mỹ, vào năm 1956 tại Hội nghị The Dartmouth. Hiểu đơn giản, AI chính là cách sử dụng công nghệ (bao gồm phần cứng và phần mềm) để mô phỏng hành vi hay ‘bắt chước’ trí thông minh của con người. Nếu con người ngày càng trở nên thông minh hơn nhờ học hỏi từ kinh nghiệm thực tế kết hợp với logic của não bộ phản ứng với kinh nghiệm đó thì AI cũng vậy. Kinh nghiệm chính là dữ liệu (data) và logic của não bộ chính là (mô hình/thuật toán AI). Thậm chí, trên một số khía cạnh, nếu dữ liệu đủ lớn và đa dạng kết hợp với một siêu thuật toán thì AI có thể thông minh hơn con người, và ChatGPT là một ví dụ điển hình gần đây.
Theo Forbes, 83% Giám đốc điều hành tin rằng AI là ưu tiên chiến lược cho doanh nghiệp của họ ngày nay, trong khi 75% Giám đốc điều hành nói rằng AI sẽ cho phép họ chuyển giao sang mô hình kinh doanh mới cùng với nhiều thử thách mới mẻ. Song song với cuộc đua AI giữa các công ty công nghệ, ngày càng có nhiều công ty quan tâm và ứng dụng công nghệ AI trong quy trình vận hành. Tận dụng những “năng lực” không giới hạn của AI, các doanh nghiệp hướng đến mục tiêu tối ưu chi phí, tăng hiệu quả công việc và nâng cao trải nghiệm người dùng.
Tại VTI, team AI chúng tôi cũng đang thực hiện các bài toán thực tiễn để phục vụ doanh nghiệp nâng cao hiệu quả trong công việc, tự động hóa những công việc có tính lặp lại và nâng cao trải nghiệm người dùng.
2. Tổng quan về ML
Các dạng ML thường được chia ra dựa trên các yếu tố sau:
- Huấn luyện dựa trên sự giám sát của con người hoặc không (Supervised Learning – học có giám sát, Unsupervised Larning – học không giám sát và Reinforcement Learning – học củng cố).
- Học dần dần hay học một cách nhanh chóng (Online vs Batch learning).
- Học và so sánh mối quan hệ của các điểm dữ liệu mới với các điểm dữ liệu đã biết, hoặc phát triển mô hình để đưa ra dự đoán dựa trên các điểm dữ liệu đã biết (Instance-based vs Model-based learning).
Tuy nhiên, trong series này tôi sẽ tập trung làm rõ 2 dạng chính của ML là Supervised Learning và Unsupervised Learning.
2.1. Supervised Learning
Trong Supervised learning, dữ liệu training (training data) đưa vào thuật toán ML cần kèm theo một cặp giả sử là (x, y), x là một instance và y là label cho instance đó, hay còn gọi là labeled dataset. Từ các cặp (x, y) khác nhau sẽ định nghĩa cho bài toán cần làm, ví dụ:
| Input(x) | Output(y) | Application |
|---|---|---|
| Spam(0/1) | Spam filtering | |
| English | Vietnamese | Machine translation |
| Audio | Text transcript | Speech recognition |
| Image | Dog | Image classification |
Mục tiêu: tìm/dự đoán label cho một instance mới thông qua các cặp (x,y) đã training.
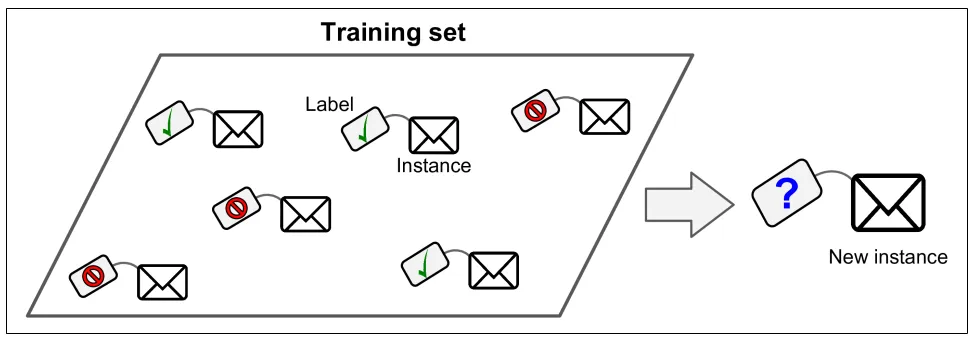
Hình 1. Ví dụ bài toán Spam filtering (Supervised learning)
Một số thuật toán nổi bật:
- k-Nearest Neighbors
- Linear Regression
- Logistic Regression
- Support Vector Machines (SVMs)
- Decision Trees and Random Forests
- Neural networks
2.2. Unsupervised Learning
Trong Unsupervised learning, dữ liệu training (training data) đưa vào thuật toán ML chỉ là instance x, hay còn gọi là unlabeled dataset. Từ x sẽ định nghĩa cho bài toán cần làm như: phân nhóm khách hàng, phát hiện bất thường, hay trực quan hóa dữ liệu, …
Ví dụ training data chưa có label:
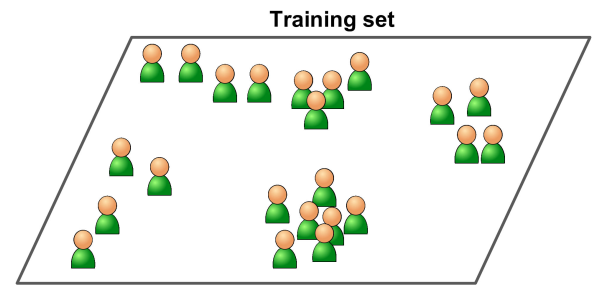
Hình 2. Ví dụ bài toán phân khúc khách hàng (Unsupervised Learning)
Ta cần phân nhóm training data thành các cụm khác nhau như sau:
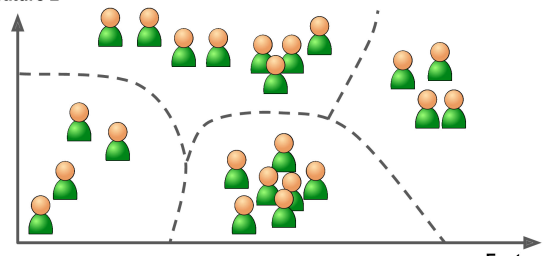
Hình 3. Kết quả bài toán phân khúc khách hàng (Unsupervised Learning)
Một số thuật toán nổi bật:
-
Clustering (phân cụm)
- K-means
- DBSCAN
- Hierarchical Cluster Analysis (HCA)
-
Anomaly/novelty detection (phát hiện bất thường/tính mới)
- One-class SVM
- Isolation Forest
-
Data visualization (trực quan hóa dữ liệu) hoặc dimensionality reduction (giảm chiều dữ liệu)
- Principal Component Analysis (PCA)
- Kernel PCA
- Locally-Linear Embedding (LLE)
- t-distributed Stochastic Neighbor Embedding (t-SNE)
Qua các phần trên, tôi đã sơ lược cơ bản và tổng quan một số góc nhìn về AI hiện nay cũng như tóm tắt về các dạng cơ bản của ML. Ở các phần tiếp theo, tôi sẽ trình bày về thuật toán Linear Regression, bao gồm cách thức hoạt động, ứng dụng và đánh giá thuật toán này.
3. Linear Regression
3.1. Định nghĩa
Hồi quy tuyến tính (Linear Regression) là một thuật toán căn bản nhất đối với bất kì ai bắt đầu học về AI. Trong thực tế, bài toán hồi quy tuyến tính được ứng dụng rất nhiều vì tính dễ dàng mô tả và dễ dàng triển khai. Hồi quy nói chung là lớp bài toán thuộc học có giám sát (Supervised Learning). Dựa trên dữ liệu có sẵn (tức giá trị mục tiêu đã biết) và sự phụ thuộc của giá trị đầu vào để dự đoán một giá trị mới.
Ví dụ minh họa: Dự đoán giá nhà dựa trên diện tích (hình bên dưới). Các điểm màu đỏ là dữ liệu về giá nhà và diện tích tương ứng trong quá khứ, điểm màu xanh biểu diễn cho giá nhà cần dự đoán khi biết diện tích, và đường thẳng màu xanh lá là đường thẳng (hàm dự đoán) mà ta cần đi tìm để fit với các điểm màu đỏ nhất có thể (đọc tới đây nếu bạn chưa hiểu, đừng lo, hãy cố gắng tiếp tục đọc các phần sau).
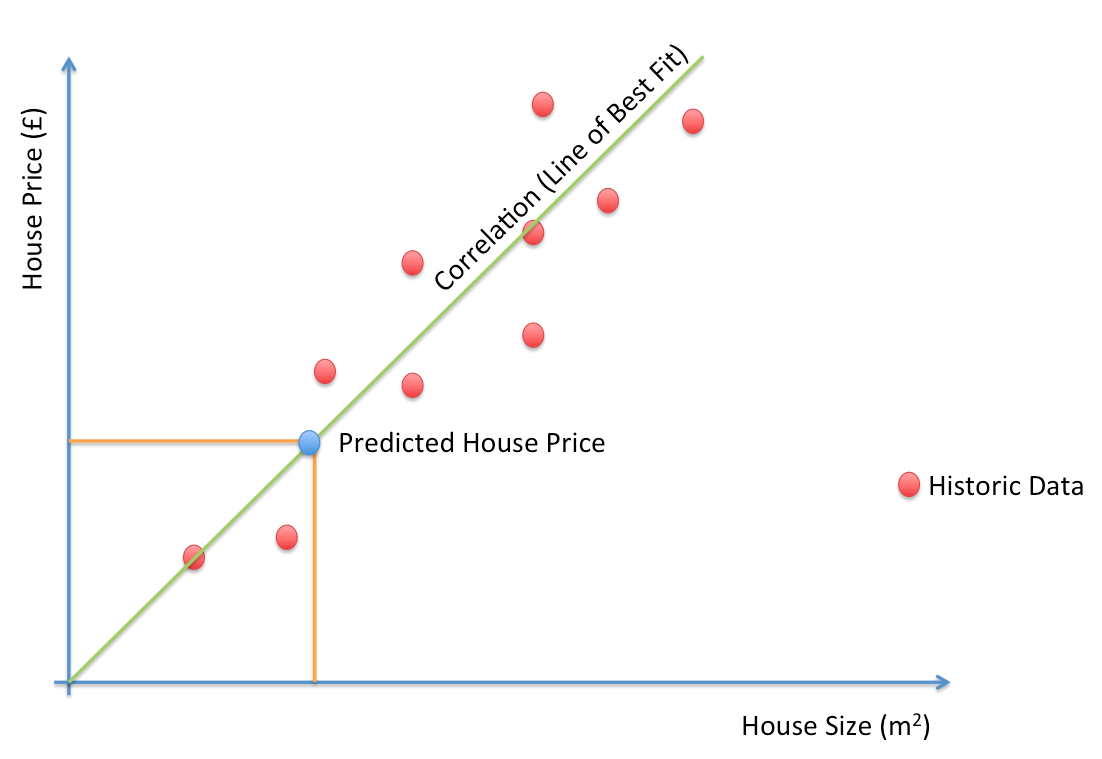
Hình 4. Ví dụ bài toán dự đoán giá nhà sử dụng Linear Regression
3.2. Hàm mất mát
Khi nhắc đến giá trị dự đoán thì giá trị sai số luôn luôn được kèm theo. Sai số tức sự khác biệt giữa giá trị dự đoán và giá trị thực. Sai số càng nhỏ chứng tỏ giá trị dự đoán càng chính xác. Đây cũng là mục tiêu của hàm mất mát (Loss function) nhằm giảm thiểu sai số tối đa nhất có thể.
Nếu đã từng có kinh nghiệm với ML, chắc hẳn bạn đã từng nghe tới Loss function hay Cost function. Loss function chỉ sai số của một điểm dữ liệu còn cost function sẽ chỉ ra trung bình sai số trên toàn tập dữ liệu. Đây là những thuật ngữ cơ bản và rất quan trọng trong ML.
Giả sử  là giá trị thực của một căn hộ, là giá trị dự đoán và là sai số khi dự đoán. Điều ta mong muốn là làm sao cho phương trình sau xảy ra:
là giá trị thực của một căn hộ, là giá trị dự đoán và là sai số khi dự đoán. Điều ta mong muốn là làm sao cho phương trình sau xảy ra:
Và trong bài toán hồi quy tuyến tính (Linear Regression) chúng ta cần tối ưu sao cho có giá trị nhỏ nhất có thể. Phương trình cần tối ưu trong bài toán:
4. Lập công thức chung
Nếu bạn không quan tâm tới Toán học và muốn có kết quả thực nghiệm nhanh chóng, bạn có thể bỏ qua phần này và bắt đầu đọc từ phần 4.3.
Với bài toán dự đoán giá nhà dựa trên diện tích, ta có:
- Hàm dự đoán trên từng điểm dữ liệu:
trong đó biểu diễn giá trị diện tích, biểu diễn giá trị dự đoán tương ứng của mẫu dữ liệu thứ , và là trọng số cần tìm.
- Hàm mất mát:
trong đó là số lượng dữ liệu, là giá trị thực của mẫu dữ liệu thứ .
Lúc này khi đã định nghĩa được 2 hàm số trên, chúng ta có thể đi tìm nghiệm cho bài toán tức tìm và . Với bài toán này, có nhiều phương pháp để tìm nghiệm. Các phương pháp dựa trên toán hình học, đại số tuyến tính và giải tích. Trong bài này, tôi sẽ trình bày 2 phương pháp: hình học và đại số tuyến tính.
4.1. Hình học
Cho 3 điểm dữ liệu và đường màu xanh chính là đường thẳng ta cần tìm, ta có:
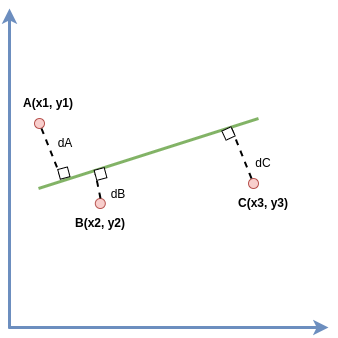
Giả sử đường thẳng màu đỏ đi qua 3 điểm A,B,C thì ta có 3 phương 2 ẩn và :
(1) (2) (3)
Nhưng với 3 phương trình 2 ẩn thì việc tìm nghiệm chính xác là điều không thể, vì vậy ta sẽ đi tìm và gần đúng sao cho sai số là bé nhất từ đó các nhà toán học đã đưa ra một giá trị cần tối ưu
Từ (1), (2), (3) ta có thể vector hóa dưới dạng: . Đặt , . Lúc này biểu diễn dưới dạng hình học ta sẽ được:
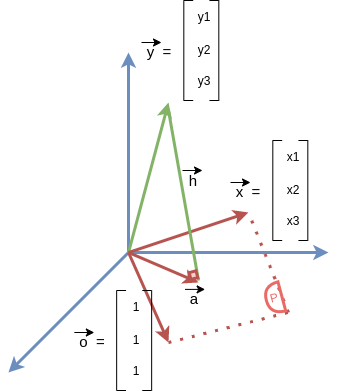
Với những giá trị khác nhau của và ta sẽ thu được mặt phẳng , vế phải của phương trình (4) sẽ tạo được một vector nằm trong mặt phẳng . Do đó, ta cần tìm và để và gần nhau nhất. Để điều kiện này xảy ra khi và chỉ khi chính là hình chiếu của lên mặt phẳng , gọi vector hình chiếu đó là .
Lúc này ta có và (tính chất của đường thẳng vuông góc mặt phẳng) và
Đặt và , theo (5) thì ta được mà (tính chất cộng vector)
Lại có (Lưu ý: dấu . biểu diễn dot product).
Tới đây chúng ta đã tìm được W là vector chứa 2 giá trị và .
4.2. Đại số tuyến tính
Để cho dễ dàng triển khai code ở phần sau, thì bắt đầu từ phần này các dữ liệu sẽ được vector và ma trận hóa. Vì vậy các công thức liên quan cũng sẽ cho ra vector hoặc ma trận.
Cho mẫu dữ liệu đã có nhãn về giá trị diện tích và giá trị căn hộ.
Để tìm nghiệm tối ưu bài toán, ta sẽ đạo hàm hàm để tìm cực tiểu
4.3. Công thức tổng quát
Ta thấy nghiệm giải bằng phương pháp sử dụng đại số tuyến tính kết hợp đạo hàm cho ra nghiệm bài toán giống với phương pháp hình học trên. Phương pháp sử dụng đạo hàm này có thể mở rộng ra các thuật toán tối ưu trong machine learning như Gradient Descent.
Cuối cùng nghiệm của thuật toán Linear Regression có thể tìm được thông qua công thức tổng quát sau:
trong đó là ma trận chứa dữ liệu đầu vào kết hợp với vector cột 1, là vector đầu ra tương ứng.
5. Thực nghiệm với Python
5.1. Tìm nghiệm bằng công thức
Ở phần này tôi sẽ sử dụng công thức tổng quát đã chứng minh ở phần 4.3 để xem xét kết quả.
# Import thư viện
import numpy as np
import matplotlib.pyplot as plt
# Tạo dữ liệu
X = np.random.randint(2, 50, [30,1])
Y = 2.1*X + np.random.randint(1,10, [30,1])# Hiển thị dữ liệu
plt.xlabel('Diện tích')
plt.ylabel('Giá nhà')
plt.scatter(X, Y)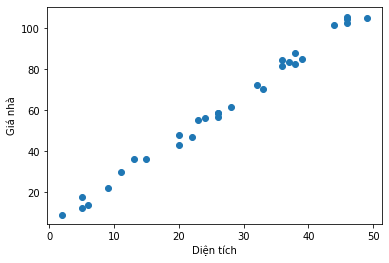
# thêm vector cột 1 vào dữ liệu input
m = X.shape[0]
ones = np.ones((m,1), dtype=np.int8)
X_t = np.concatenate((ones,X), axis=1)
# tìm nghiệm W cho bài toán
W = np.linalg.inv(X_t.T.dot(X_t)).dot(X_t.T.dot(Y))
w0,w1 = W[0][0],W[1][0]
# lấy điểm đầu và điểm cuối
# để vẽ đường thẳng cần tìm
x0 = np.linspace(2,50,2)
y0 = w0 + w1*x0
# visualize đường thẳng cần tìm
plt.scatter(X, Y)
plt.plot(x0,y0,'r')
plt.xlabel('Diện tích')
plt.ylabel('Giá nhà')
plt.show()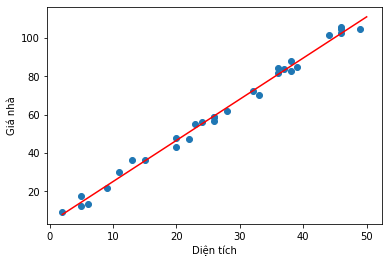
Nghiệm W ta tìm được là:
print(W)
[[3.71616416]
[2.14558686]]5.2. Tìm nghiệm bằng thư viện Sklearn
Ở phần này, tôi sẽ sử dụng một thư viện vô cùng nổi tiếng mà ai cũng biết khi làm/học ML đó là Sklearn. Từ đó so sánh kết quả nghiệm của thư viện với nghiệm của công thức bên trên tìm ra.
# Import thư viện
from sklearn.linear_model import LinearRegression
import numpy as np# Khởi tạo model
lin_reg = LinearRegression()
# Fit/train model
lin_reg.fit(X, Y)
print('w1 = {}, w0 = {}'.format(lin_reg.coef_,lin_reg.intercept_))
w1 = [[2.14558686]], w0 = [3.71616416]Ta thấy kết quả nghiệm của bài toán giữa phương pháp tự thực hiện ở phần 5.1 và thư viện scikit-learn đã đưa ra kết quả giống nhau. Sau khi tìm được nghiệm bài toán, việc tiếp theo khi có dữ liệu cần dự đoán bạn chỉ cần gọi tới hàm predict để lấy ra giá trị dự đoán. Hàm này bạn đọc hãy tự mình tìm hiểu tại đây coi như là bài tập về nhà.
6. Đánh giá và kết luận
-
Nếu bài toán có dữ liệu dạng parabol mà vẫn sử dụng hàm dự đoán là đường thẳng thì sao? Vẫn được, nhưng sai số cao, chưa thể tối ưu bằng sử dụng hàm parabol. Giả sử, đầu vào lúc này không phải là 1 chiều mà là 2 chiều thì hàm dự đoán sẽ trở thành một mặt phẳng và công thức nghiệm trên vẫn đúng. Còn đầu vào có quá nhiều chiều dữ liệu thì lúc này mô hình của bài toán sẽ là một siêu phẳng (hyper plan). Như vậy bài toán dự đoán của chúng ta đã được giải quyết bằng cách tìm nghiệm W. Để dự đoán một điểm mới ta chỉ cần áp dụng như tính y0 ở trên. Ở phần này bạn đọc có thể đọc tại đây để hiểu kĩ hơn.
-
Việc tìm ma trận nghịch đảo là điểm yếu của cách làm này vì sẽ tốn thêm time complexity (
với là số lượng features của bài toán) và space complexity . Vì vậy, trong thư viện scikit-learn các nhà phát triển đã tối ưu phương pháp giải bằng ứng dụng của thuật toán SVD – Singular Value Decomposite và đạt được tốc độ khoảng . Tuy nhiên, cả 2 phương pháp này sẽ rất chậm với những bộ dữ liệu có features cao chiều (100.000) nên sẽ phù hợp hơn với những bộ dữ liệu thấp chiều (kể cả nhiều dữ liệu) thì phương pháp này vẫn sẽ hoạt động tốt. -
Ở hàm mất mát, có một số thuật toán nhằm tránh overfiting như Ridge Regression, Lasso Regression hay trong Deep Learning là Regurlization.
-
Thuật toán này sử dụng trung bình tổng sai số của giá trị dự đoán và giá trị thật để triển khai và đánh giá, vì vậy khi tồn tại dữ liệu “nhiễu” sẽ gây ảnh hưởng tới chất lượng dự đoán. Một số phương pháp khắc phục đó là sử dụng: MAE Loss, Huber Loss… Nhưng vì các hàm này khá khó để giải trực tiếp vì vậy, thường sẽ loại bỏ các dữ liệu “nhiễu” trước khi traning.
7. Tham khảo
[1] Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow
[2] Week 2 – Machine Learning coursera by Andrew Ng
[3] Bài 3: Linear Regression – Machine Learning cơ bản by Vu Huu Tiep
[4] Bài 1: Linear Regression – Computer Science by Hoang Dinh Huy
8. Lời cảm ơn
Tôi xin gửi lời cảm ơn chân thành tới đồng nghiệp tại team AI-VTI đã có những góp ý cho bài viết này để hoàn thiện hơn. Đặc biệt gửi tới cảm ơn tới Linh Do (Linh Do Thi Thuy – VTI.MKT) đã bổ sung một góc nhìn tổng quan về AI trong bài viết này.




Vui lòng đăng nhập để bình luận.